Article
Video


The build vs. buy debate in software is nothing new. With the rise of large language models (LLMs), spinning up prototypes that can complete tasks has become easier than ever. However, developing an AI application for CX that’s scalable and production-worthy demands extra consideration. In this post, we’ll explore key questions to ask when deciding whether to build or buy generative AI solutions for CX.
While the right answer depends on industry, use case, and business goals, it’s important to carefully weigh your options.
The reason for this has a lot to do with the nature of generative AI.
Unlike most software development where the goal is to create a deterministic system with the same, expected outcome every single time, generative AI generates new information and content based on patterns, often producing varied responses that can be difficult to predict.
This variability is what makes gen AI applications so powerful, but also adds complexities in maintaining consistency and control.
Differing from standard applications where the workflow is predefined, generative AI models require continuous monitoring, training, and refinement. There is a misconception that generative AI just needs instructions. But in fact, they need much more, especially if you are training on your own data.
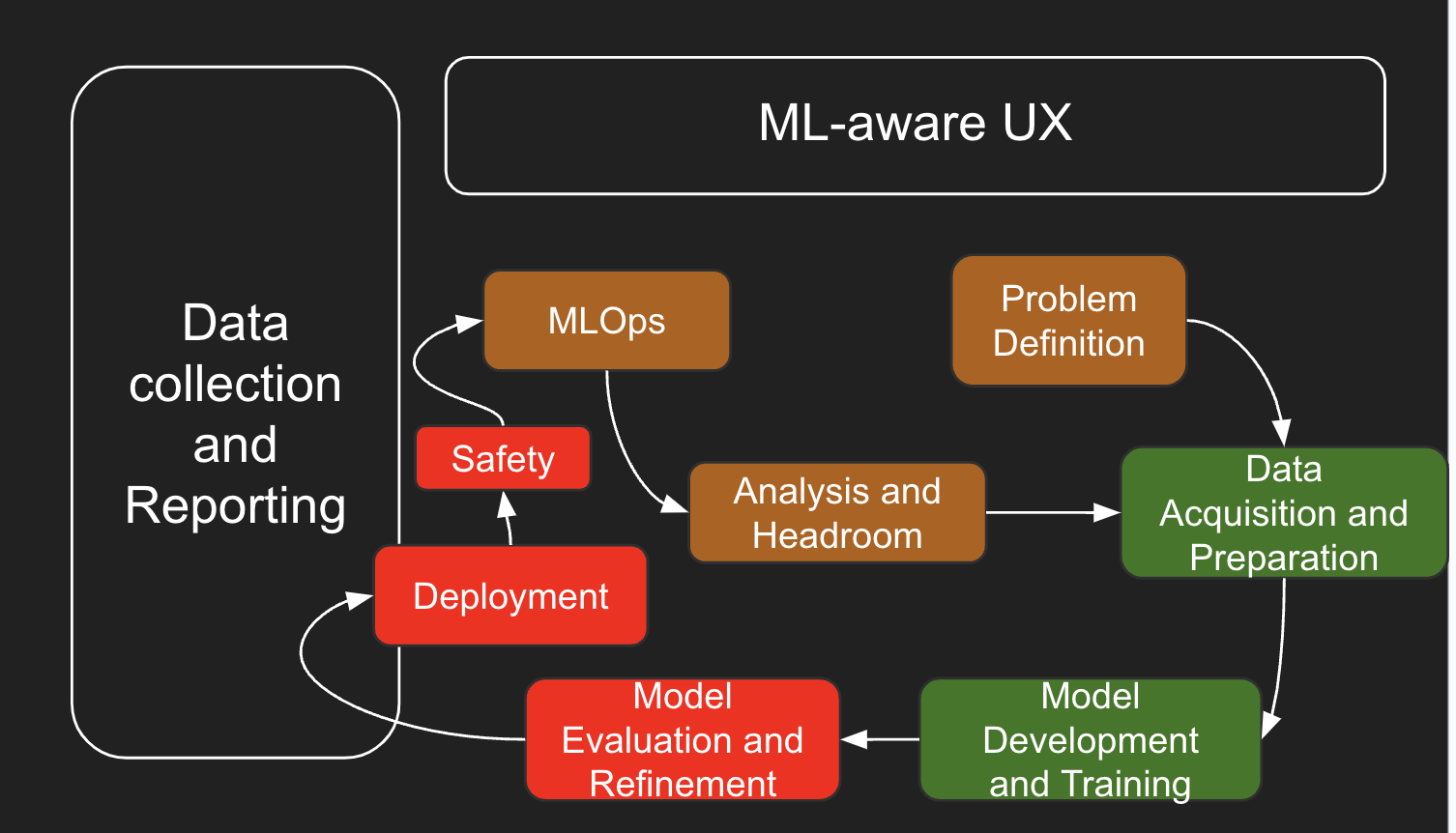
The flexibility makes them ideal for tasks that benefit from creative problem-solving or personalized engagement, but it also means that development doesn’t stop at launch. This, compounded by the fact that CX applications can ultimately impact a brand’s relationship with its customers, brings additional layers of considerations when deciding whether to build the application yourself or to partner with a vendor.
While the following is not an exhaustive list, here are some top questions you should consider when making a decision.
If building AI applications aligns with your business objectives, you’re likely prepared for both short-term and long-term investment in development and maintenance that will be absolutely critical for AI applications, ensuring the solution doesn’t become a burden on your resources.
In contrast, if developing your own AI applications isn’t a core objective, partnering with a vendor may be the more sensible approach. Vendors are equipped to provide solutions that fit your needs without the complexities of internal development, allowing you to focus on your primary business goals.
Based on McKinsey & Company’s recent estimates, building and maintaining your own foundational model could cost up to 200M with an annual recurring cost of 1-5M. Using off-the-shelf solutions or fine-tuning existing models with sector-specific knowledge can dramatically reduce this cost.
If your deployment timeline is urgent—perhaps due to a competitor already leveraging AI solutions—working with an AI solution provider can help you hit the ground running and accelerate implementation. A vendor with solid experience in enterprise AI development will help you avoid unnecessary trial and error, minimizing risks associated with AI safety - such as AI hallucinations.
Instead, leaders should strongly consider partnering with gen AI solution providers and enterprise software vendors for solutions that aren’t very complex or [industry] specific. This is particularly critical in instances where any delays in implementation will put them at a disadvantage against competitors already leveraging these services.
- McKinsey & Company, in "How generative AI could revitalize profitability for telcos"
While widely available large language models (LLMs) have significantly accelerated the process of building a working prototype on a laptop, this does not equate to having a production-ready, scalable solution that can effectively address your business needs [link to last mile]. Additionally, the demand for ongoing maintenance means that development does not stop after the application is launched.
Developing AI applications requires a skilled team knowledgeable in machine learning, data management, and software engineering, along with the necessary technological resources and datasets. Even choosing the right LLM to use for the best fitted use cases would require a good understanding of how various LLMs differ. Experience working with AI solutions is also crucial for successful deployment in an enterprise context.
In the last two months, people have started to understand that LLMs, open source or not, could have different characteristics, that you can even have smaller ones that work better for specific scenarios
- Docugami CEO Jean Paoli, in CIO “Should you build or buy generative AI”
If your organization lacks this expertise or the infrastructure to support such a project - not just at the prototype stage, but also to scale, monitor, and maintain the solution in the future - it may be more prudent to consider vendor solutions that can provide the capabilities you need without overextending your internal teams.
Also consider, if problems arise, do you have the manpower and expertise to investigate the root cause and implement long-term fixes, or will you be crossing your fingers and hoping the issues don’t recur? A strong internal team capable of addressing challenges as they emerge is necessary for ensuring the reliability and effectiveness of your AI application for CX. Without this capability, you risk operational disruptions and even diminishing trust in your brand.
When considering your expected return from an AI investment, it’s essential to balance potential returns with the associated risks.
Agent-facing projects generally carry lower risks, as the AI solution won’t directly interact with customers. This allows for more trial and error, with agents able to provide feedback on the AI application’s performance. That said, such solutions might yield only incremental gains in agent productivity with less or no impact on the customer experience, and do not take advantage of the full capabilities of gen AI.
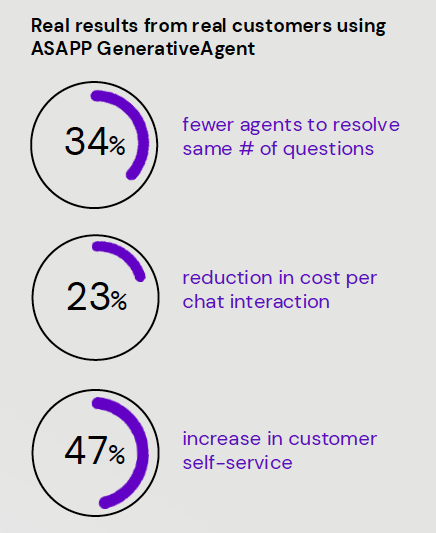
In contrast, customer-facing gen AI applications can offer a much better return because they can directly improve customers’ ability to self-service and, in some cases, resolve their issues directly. Here are the kinds of results a customer got when deploying generative AI agents with the capability to resolve Tier-one tasks.
Allowing AI to handle a broader range of tasks introduces added complexity. While there are risks—such as AI hallucination, where the system may generate incorrect or irrelevant responses—these challenges can be managed with the right approach. Having a strong internal team that can tackle this, or choosing an experienced vendor with a well-informed strategy for handling AI behavior, will ensure guardrails are placed around customer-facing interactions — so you can get the most out of your AI applications with confidence.
Ultimately, the choice between building or buying an AI solution should align with your organization’s long-term vision. Each option carries its own set of challenges and opportunities, and taking the time to assess your specific needs can set the stage for success.
Considering the evolving landscape of AI, it's not just about deploying technology, but also ensuring that it fits well into your operational framework and readies you for the future. With careful evaluation, you can make a choice that enhances your customer experience. Whether you decide to build or partner, the key is to stay focused on your goals and embrace a strategic approach to generative AI applications.
The term “hallucination” has become both a buzzword and a significant concern. Unlike traditional IT systems, Generative AI can produce a wide range of outputs based on its inputs, often leading to unexpected and sometimes incorrect responses. This unpredictability is what makes Generative AI both powerful and risky. In this blog post, we will explore what hallucinations are, why they occur, and how to ensure that AI responses are safely grounded to prevent these errors.
In the context of Generative AI, a hallucination refers to an output that is not grounded in the input data or the knowledge base the AI is supposed to rely on. Hallucinations can be broadly categorized into two types:
To better understand hallucinations, we can consider two axes. Justification - whether the AI had information indicating that its statement was true. And truthfulness - whether the statement was actually true.
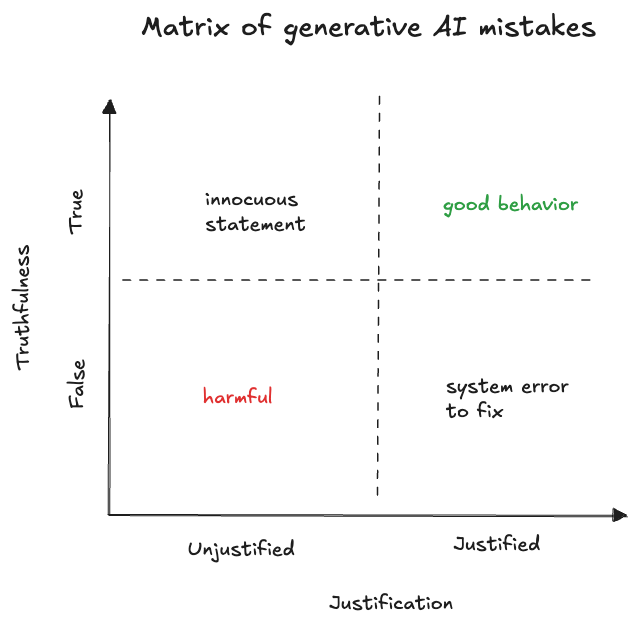
Based on these axes, we can classify hallucinations into four categories:
Hallucinations in generative AI occur due to several reasons. Generative models are inherently stochastic, meaning they can produce different outputs for the same input. Additionally, the large output space of these models increases the likelihood of errors, as they are capable of generating a wide range of responses. AI systems that rely on incomplete or outdated data are also prone to making incorrect statements. Finally, the complexity of instructions can result in misinterpretation, which may cause the model to generate unjustified responses.
We typically think about four pillars when it comes to preventing and managing hallucinations:
One of the most effective ways to prevent hallucinations is to ensure that AI responses are grounded in reliable data. This can be achieved through:
To minimize the risk of hallucinations, several safety mechanisms can be implemented:
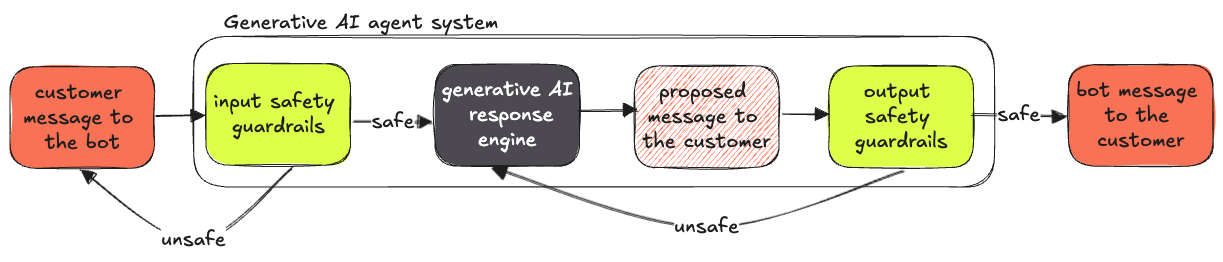
A separate post-production model can be used to classify AI responses as mistakes in more detail. While the “catching hallucination” model should balance effectiveness with latency, the post-production mistake monitoring model can be much larger, as latency is not a concern.
A well-defined hallucination taxonomy is crucial for systematically identifying, categorizing, and addressing errors in Generative AI systems. By having a well-defined error taxonomy system, users can aggregate reports that make it easy to identify, prioritize, and resolve issues quickly.
The following categories help identify the type of error, its source of misinformation, and the impact.
Continuous improvement is crucial for managing and reducing hallucinations in AI systems. This involves several key practices. Regular updates ensure that the AI system is regularly updated with the latest data and information. Implementing feedback loops allows for the reporting and analysis of errors, which helps improve the system over time. Regular training and retraining of the AI model are essential to enable it to adapt to new data and scenarios. Finally, human oversight involving contact center supervisors to review and correct AI responses, especially in high-stakes situations, is critical.
By understanding the nature of hallucinations and implementing robust mechanisms to prevent, catch, and manage them, organizations can harness the power of Generative AI while minimizing risks. Just as human agents in contact centers are managed and coached to improve performance, Generative AI systems can also be continually refined to ensure they deliver accurate and reliable responses. By focusing on grounding responses in reliable data, employing safety mechanisms, and fostering continuous improvement, we can ensure that AI responses are safely grounded and free from harmful hallucinations.
The advent of commercially available cloud-hosted large language models (LLMs) such as OpenAI’s GPT-4o and Anthropic’s Claude family of models has completely changed how we solve business problems using machine learning. Large pre-trained models produce state-of-the-art results on many typical natural language processing (NLP) tasks such as question answering or summarization out-of-the-box. Agentic AI systems built on top of these LLMs incorporate tool usage and allow LLMs to perform goal-directed tasks and manipulate data autonomously, for example by using APIs to connect to the company knowledge base, or querying databases.
The extension of these powerful capabilities to audio and video has already started, and will endow these models with the ability to make inferences or generate multi-modal output (produce responses not only in text, but also audio, image, and video) based on complex, multi-modal input. As massive as these models are, the cost and the time it takes to produce outputs is decreasing rapidly, and this trend is expected to continue.
While the barrier to entry is now much lower, applying AI across an enterprise is no straightforward task. It’s necessary to consider hidden costs and risks involved in managing such solutions for the long-term. In this article, we will explore the challenges and considerations involved in building your own enterprise-grade AI solutions using LLMs, and look at a contact center example.
LLMs have served to raise the level of abstraction at which AI practitioners can create solutions. Tremendously so. Problems that took immense time, skill, experience and effort to solve using machine learning (ML) are now trivial to solve on a laptop. This makes it tempting to think of the authoring of a prompt as being equivalent to the development of a feature, replacing the prior complex and time-consuming development process.

However, showing that something can be done isn’t quite the same as a production-worthy, scalable solution to a business problem.
For one, how do you know you have solved the problem? It is common practice to create a high-quality dataset for training and evaluating the model. While the creation of such a benchmark takes time and effort, it is standard practice. Since LLMs come pretrained, such a dataset is no longer needed for training. Impressive looking results can be obtained with little effort - but without anchoring results to data, the actual performance is unknown.
Creating the evaluation methodology for a generative model is much harder because the potential output space is tremendous. In addition, evaluation of output is much more subjective. These problems can be addressed, for example, using techniques such as “LLM as a judge”, but the evaluation becomes a demanding task - as the evaluator itself becomes a component to build, tune and maintain.
The need to continuously monitor quality requires the creation of complex data pipelines to sample model outputs from a production system, sending these to a specialized evaluation system, and tracking the scores. The method for sampling data - such as the data distribution desired, the adjustment of the sampling frequency so that it is appropriate (sampling and measuring quality often on a large amount of data may give more confidence in the quality, but would be expensive), considerations around protecting data in transit and retaining it based on policies all add to the complexity. In addition, the instructions for scoring, interpretation of the scores, type of LLM used for scoring, type of input data and so on can all change often.
A fantastic-looking prototype or demo running on a laptop is very promising, but it is the first step in a long journey that allows you to be assured of the quality of the models’ outputs in a production system.

In effect, the real work of preparing and annotating data to create a reliable evaluation takes place after the development of the initial prompt that shows promising results.
- Nirmal Mukhi, VP AI Engineering

The generality and power of LLMs is a double-edged sword. Ultimately, they are models that predict and generate the text that, based on the huge amount of pre-trained data they have been exposed to, best matches the context and instructions they are given - they will “do their best” to produce an answer. But they don’t have any in-built notion of confidence or accuracy.
They can hallucinate, that is, generate outputs that make completely baseless claims not supported by the provided context. Some hallucinations could be harmless, while others could have detrimental consequences and can risk damaging the brand.
Hallucinations can be minimized with clever system design and by following the best practices in prompting (instructions to the LLM). But the chances of hallucinating are always non-zero; it is a fundamental limitation of how LLMs work. Hence, it becomes imperative to monitor them, and continuously attempt to improve the hallucination prevention approach, whatever that may be.
Beyond hallucinations, since LLMs can do so many things, getting them to “stay on script” when solving a problem can be challenging. An LLM being used to answer questions about insurance policies could also answer questions about Newton’s laws - and constraining it to a domain is akin to teaching an elephant to balance on a tightrope. It’s trying to limit an immensely powerful tool to narrow its focus to one problem, such as the customer query that they need to resolve right in front of them.
One solution to these problems is to fine-tune an LLM so that it is “better behaved” at solving a specific problem. The process of fine-tuning involves collecting high-quality data that allows the model to be trained to follow specific behaviors, following techniques such as few-shot learning, or Reinforcement Learning with Human Feedback (RLHF). Doing so however takes specialized skills: even assembling an appropriate dataset can be challenging; ideally, fine-tuning would be a periodic if not continuous process - and this is difficult to achieve. Thus, managing a large number of fine-tuned models and keeping them up to date will require specialized skills, expertise, and resources.
While LLMs can do amazing things, they cannot do everything. Their reasoning and math capabilities can fail. Even a task like text matching can be hard to get right with an LLM (or at any rate can be much more easily and reliably solved with a regular expression matcher). So they aren’t always the right tool to use, even for NLP problems. These issues are inherent to how LLMs work. They are probabilistic systems that are optimized for generating a sequence of words, and are thus ill-suited for tasks that are completely deterministic.
Sophisticated prompting techniques can be designed to work around some of these limitations. Another approach is to attempt to solve a multi-step problem that involves complex reasoning using agentic orchestration. A different approach would allow for a model pipeline where tasks suited to being solved using LLMs are routed to LLMs, while tasks suited to being solved via a deterministic system or regular expression matcher are routed to other models. Identifying and designing for these situations is a requirement to support a diversity of use cases.
While vendors like OpenAI and Anthropic have made LLMs relatively cheap to run, they still use complex serving architecture and hardware. Many such LLM hosting platforms are still in beta, and typical service level agreements (SLAs), when supported, promise far below 99.99% availability (rarely guaranteed). This risk can be managed by adding fallbacks and other mechanisms, and represents additional effort to build a production system.
And, in the end, building on LLMs is all software development and needs to follow standard software development processes. An LLM or even just a prompt is an artifact that has to be authored, evaluated, versioned, and released carefully just like any software artifact or ML model. You need observability, the ability to conduct experiments, auditability and so on. While this is all fairly standard, the discipline of MLOps introduces an additional layer of complexity because of the need to continuously monitor and tune for safety (including security concerns like prompt injection) and hallucinations. Additional resources need to be made available to handle such tasks.
Consider the problem of offering conversation summarization for all your conversations with customers, across voice and digital channels. The NLP problem to be solved here, that of abstractive summarization on multi-participant conversations with a potentially large number of turns, was difficult to solve as recently as 2021. Now, it is trivial to address using LLMs - writing a suitable prompt for an LLM to produce a summary that superficially looks high quality is easy.
But how good would the generated summaries be at scale as an enterprise solution? It is possible that the LLM might hallucinate and generate summaries that could include completely fictitious information that’s not easily discerned from the conversation itself. But would that happen 1% of the time, or 0.001% of the time…and how harmful would those hallucinations be? Adding the actual number of interactions into consideration, a 1% rate could mean 1 customer interaction out of 100, but as you scale up the interactions you could suddenly be faced with 1000 customers out of 100,000 interactions. Evaluating the quality of the prompt, and optimizing it, would require the creation of an evaluation dataset. Detecting hallucinations and classifying them into different categories so that they can be mitigated would take extra effort - and preventing or at least minimizing the chances that they occur, even more so.
Summarization could be solved using just about any good LLM - but which one would provide the best balance between cost and quality? That’s not a simple question to answer - it would require the availability of an evaluation dataset, followed by a lot of trials with different models and applications of prompt optimization.
A one-size-fits-all summary output rarely meets the needs of an enterprise. For example, the line of business responsible for handling customer care may want the summary to explicitly include details on any promised follow-up in the case of a complaint. The line of business responsible for sales may want to include information about promotions offered or whether the customer purchased the product or service, and so on. Serving these requirements would mean managing intricate configurations down to having different prompts to serve different use cases, or ideally fine-tuned LLMs that better serve the specific needs of these businesses. These requirements may change often, and so would need for versioning, change management and careful rollouts.
Summary quality would need to be monitored, and as changes in technology (such as improvements in models, inference servers or hardware) occur, things would need to be updated. Consider the availability of a new LLM that is launched with a lot of buzz in the industry. It would have to be evaluated to determine its effectiveness at summarization of the sort you are doing - which would mean updating the various prompts underlying the system, and checking this model’s output against the evaluation dataset, itself compiled from samples of data from a variety of use cases. Let’s say that it appears to produce higher quality summaries at a lower price on the evaluation dataset, and a decision is taken to roll it into production. This would have to be monitored and the expected boost in performance and reduction in price verified. In case something does go wrong (say it is cheaper and better…but takes unacceptably long and customers complain about the latency of producing summaries), it would need to be rolled back.
What about feedback loops? Perhaps summaries could be rated, or they could be edited. Edited summaries or highly rated ones could be used to fine tune a model to improve performance or lower cost by moving to a smaller, fine-tuned model.
This is not an exhaustive list of considerations - and this example is only about summarization, which is a ubiquitous, commodity capability in the LLM world. More complex use cases requiring agentic orchestration with far more sophisticated prompting techniques require more thought and effort to deploy responsibly.
Pre-trained foundational large language models have changed the paradigm of how ML solutions are built. But, as always, there’s no free lunch. Enterprises attempting to build from scratch using LLMs have to account for the total lifetime cost of maintaining such a solution from a business standpoint.

There is a point early in the deployment of an LLM-based solution where things look great - hallucinations haven’t been noticed, edge cases haven’t been encountered, and the value being derived is significant. However, this can lead to a false confidence, and under-investing at this stage is a dangerous fallacy. Without sufficient continued investment, the risk of having this solution in production without the necessary fallbacks, safeguards and flexibility will be an ever-present non-linear risk. Going beyond prototyping is therefore harder than it might seem.
An apt analogy is architecting a data center. Purchasing commodity hardware, and using open source software for running servers, managing clusters, setting up virtualization, and so on are all possible. But putting that package together and maintaining it for the long haul is enough of a burden that enterprises would prefer to use public cloud providers in most cases.
Similarly, when choosing whether to build AI solutions or partner with vendors who have the experience deploying enterprise solutions, organizations should be clear-eyed about the choices they are making, understand the long-term costs and the tradeoff associated with them.
There’s been a huge explosion in large language models (LLMs) over the past two years. It can be hard to keep up – much less figure out where the real value is happening. The performance of these LLMs is impressive, but how do they deliver consistent and reliable business results?
OpenAI demonstrated that very, very large models, trained on very large amounts of data, can be surprisingly useful. Since then, there’s been a lot of innovation in the commercial and open-source spaces; it seems like every other day there’s a new model that beats others on public benchmarks.
These days, most of the innovation in LLMs isn’t even really coming from the language part. It’s coming in three different places:
Two really exciting things emerge out of these innovations. First, it’s much easier to create prototypes of new solutions – instead of needing to collect data to make a Machine Learning (ML) model, you can just write a specification, or in other words, a prompt. Many solution providers are jumping on that quick prototyping process to roll out new features, which simply “wrap” a LLM and a prompt. Because the process is so fast and inexpensive, these so-called “feature factories” can create a bunch of new features and then see what sticks.
Second, making LLMs useful in real time relies on the LLM not using its “intrinsic knowledge” – that is, what it learned during training. It is more valuable instead to feed it contextually relevant data, and then have it produce a response based on that data. This is commonly called retrieval augmented generation, or RAG. So as a result, there are many companies making it easier to put your data inside the LLM – connecting it to search engines, databases, and more.
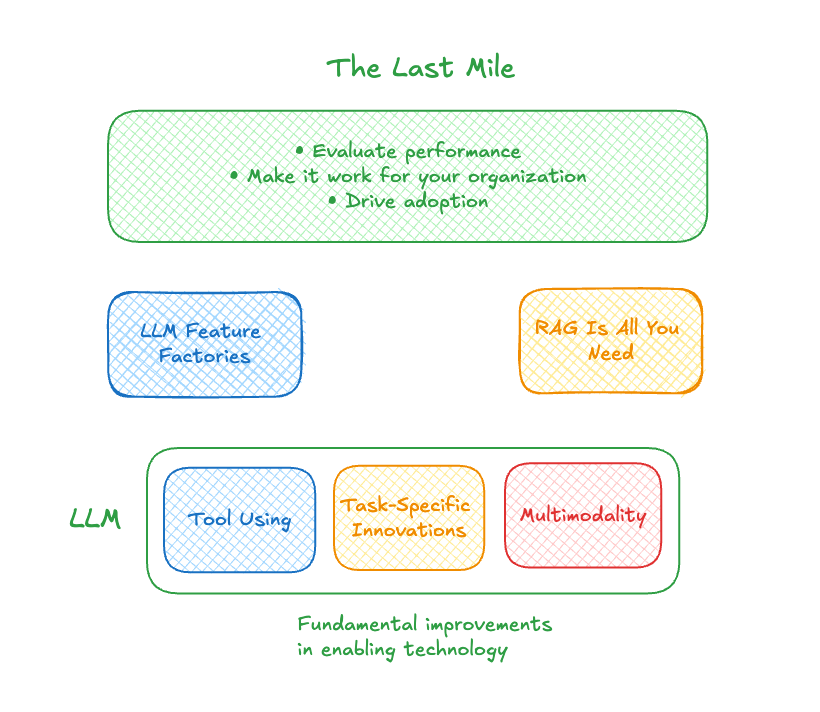
The thing about these rapidly developed capabilities is that they always place the burden of making the technology work on you and your organization. You need to evaluate if the LLM-based feature works for your business. You need to determine if the RAG-type solution solves a problem you have. And you need to figure out how to drive adoption. How do you then evaluate the performance of those things? And how many edge cases do you have to test to make sure it is dependable?
This “last mile” in the AI solution development and deployment process costs time and resources. It also requires specific expertise to get it right.
High-quality LLMs are widely available. Their performance is dramatically improved by RAG. And it’s easier than ever to spin up new prototypes. That still doesn’t make it easy to develop a customer-facing generative AI solution that delivers reliable value. Enabling all of this new technology - namely, LLMs capable of using contextually relevant tools at their disposal - requires expertise to make sure that it works, and that it doesn’t cause more problems than it solves.
It takes a deep understanding of the performance of each system, how customers interact with the system, and how to reliably configure and customize the solution for your business. This expertise is where the real value comes from.
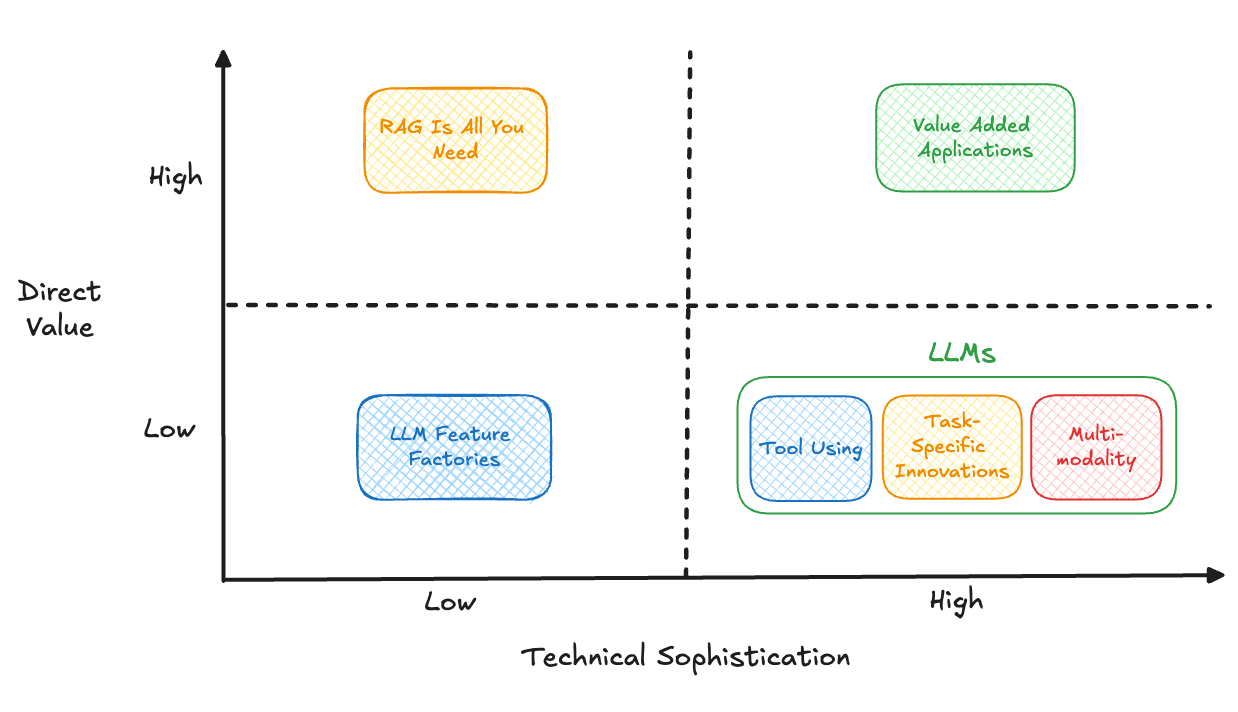
Plenty of solution providers can stand up an AI agent that uses the best LLMs enhanced with RAG to answer customers’ questions. But not all of them cover that last mile to make everything work for contact center purposes, and to work well, such that you can confidently deploy it to your customers, without worrying about your AI agent mishandling queries and causing customer frustration.
Generative AI services provided by the major public cloud providers can offer foundational capabilities. And feature factories churn out a lot of products. But neither one gets you across the finish line with a generative AI agent you can trust. Developing solutions that add value requires investing in input safety, output safety, appropriate language, task adherence, solution effectiveness, continued monitoring and refining, and more. And it takes significant technical sophistication to optimize the system to work for real consumers.
That should narrow your list of viable vendors for generative AI agents to those that don’t abandon you in the last mile.
Ever heard the phrase, "Customer service is broken?"
It's melodramatic, right? —something a Southern lawyer might declaim with a raised finger. Regardless, there’s some truth to it, and the reason is a deadly combination of interaction volume and staffing issues. Too many inbound interactions, too few people to handle them. The demands of scale do, in fact, break customer service.
This challenge of scaling up is a natural phenomenon. You find it everywhere, from customer service to pizza parlors.
If you want to scale a pizza, you have to stretch the dough, but you can't stretch it infinitely. There’s a limit. Stretch it too far, and it breaks.
Customer service isn't exactly physical, but physical beings deliver it— the kind who have bad days, sickness, and fatigue. When you stretch physical things too far (like balloons, hamstrings, or contact center agents), they break. In contact centers, broken agents lead to broken customer service.
Contact centers are currently stretched pretty thin. Sixty-three percent of them face staffing shortages. Why are they struggling? Some cite rising churn rates year after year. Others note shrinking agent workforces in North America and Europe. While workers flee agent jobs for coding classes, pastry school, and duck farming, customer request volumes are up. In 2022, McKinsey reported that 61% of customer care leaders claimed a growth in total calls.
To put it in pizza terms (because why not?), your agent dough ball is shrinking even as your customers' insatiable pizza appetite expands.
What’s a contact center to do? There are two predominant strategies right now:
Contact centers seem intent on squeezing more out of their digital self-service capabilities in an attempt to contain interactions and shrink agent queues. At the same time, they’re feverishly investing in technology to expand capacity with performance management, process automation and real-time agent support.
But even with both of these strategies working at full force, contact centers are struggling to keep up. Interaction volume continues to increase, while agent turnover carries on unabated. Too much appetite. Not enough dough to go around.
Here’s the harsh reality – interaction volume isn’t going to slow down. Customers will always need support and service, and traditional self-service options can’t handle the scope and complexity of their needs. We’ll never reduce the appetite for customer service enough to solve the problem.
We need more dough. And that means we need to understand the recipe for customer service and find a way to scale it. The recipe is no secret. It’s what your best agents do every day:
The real question is, how do we scale the recipe up when staffing is already a serious challenge?
We need to scale up capacity in the contact center without scaling up the workforce. Until recently, that idea was little more than a pipe dream. But the emergence of generative AI agents has created new opportunities to solve the long-running problem of agent attrition and its impact on CX.
Generative AI agents are a perfect match for the task. Like your best human agents, they can and should listen, understand, propose solutions, and take action to resolve customers’ issues. When you combine these foundational capabilities into a generative AI agent to automate customer interactions, you expand your contact center’s capacity – without having to hire additional agents.
Here’s how generative AI tools can and should help you scale up the recipe for customer service:
Many contact centers are already using generative AI to listen, understand, and propose. But it’s generative AI’s ability to take action based on those other qualities that dramatically stretches contact center capacity (without breaking your agents).
A growing number of brands have already rolled out fully capable generative AI agents that handle Tier 1 customer interactions autonomously from start to finish. That does more than augment your agents’ capabilities or increase efficiency in your workflows. It expands your frontline team without the endless drain of recruiting, onboarding, and training caused by high agent turnover.
A single generative AI agent can handle multiple interactions at the same time. And when paired with a human agent who provides direct oversight, a generative AI agent can achieve one-to-many concurrency even with voice interactions. So when inbound volume spikes, your generative AI agent scales up to handle it.
More dough. More capacity. All without stretching your employees to the breaking point. For contact center leaders, that really might be as good as pizza for life.
Agent churn rates are historically high, and the problem persists no matter what we throw at it — greater schedule flexibility, gamified performance dashboards, and even higher pay.
Instead of incremental changes to timeworn tools, what if we could bypass the problem altogether?
Download the Agent Churn: Go Through It or Around It? eBook to learn why traditional strategies for agent retention aren't working, and how generative AI enables a radical new paradigm.
Navigating any legacy platform transition can be nerve-wracking with little wiggle room for mistakes. As organizations increasingly adopt AI-powered solutions to enhance their customer experience, smoothing the process of switching platforms and optimizing user interactions requires careful planning, prioritization, and collaboration.
In the second installment of our two-part series based on a discussion between Melissa Price, VP of Customer Experience for Digital Self-Serve at Altice and Justin Mulhearn, Head of Solutions Engineering at ASAPP, we delve into the nuances of digital messaging platform transitions. Together, they share insights on overcoming challenges such as timing constraints, balancing automation with human support, and ensuring a smooth shift to a more advanced AI native platform. Through their experiences, they outline best practices for achieving long-term success while keeping user needs at the forefront.
Read Part 1: Why Altice switched messaging platforms: addressing flexibility, access, and support
* Minor edits have been made to the transcript for clarity and readability.
Nick (moderator): We spoke earlier in the week, Melissa, about some of the ways we phased out the switch from your previous digital messaging platform to an AI native platform, or even just thinking about how to start and how to optimize over time.
I'd love for you to talk a little more in detail about how we got there, some of the things that were surprising, or moments when you had to prioritize this first, then get to other things later, while keeping the longer-term plan in mind.
Melissa: So some of the areas we delved into first were really about ensuring we're providing the right intent identifications, as we talked about earlier, and that we're in all the right places. The entry points were important to us to make sure we're there when customers need us and not just in the background, hoping the customer discovers us.
Being present in those moments that matter is something we continue to refine.
Whether that's in the app as backup support, leveraging chat there, or through our website, making chat available there. One example on the website is when customers are logged out and, say, they forgot their username or password and can’t log in to pay their bill. Being there in the moment to offer chat as the next line of support helps resolve the login issue or route them to an agent to resolve the issue more directly.
Melissa: Those were the types of things we wanted to uncover—what opportunities exist to drive more containment, where we can offer a quick reply or bot-based solution to the customer. Or if it reaches the next level of support, how do we identify those opportunities and get them directly to an agent?
Containment was definitely one of our goals that we reached, but containment in the right places and in the right way, I would say, not to misinterpret that stat. In some cases, containment is not a good option, and we need to rely on our chat agents to deliver the best experience.
Then there’s the surfacing of the entry point. Those are two big areas I’d highlight: intent identification and, up front, making sure customers can get to the right flow and resolution path as quickly as possible. That's also part of the consideration in terms of what's driving the AHT reduction.
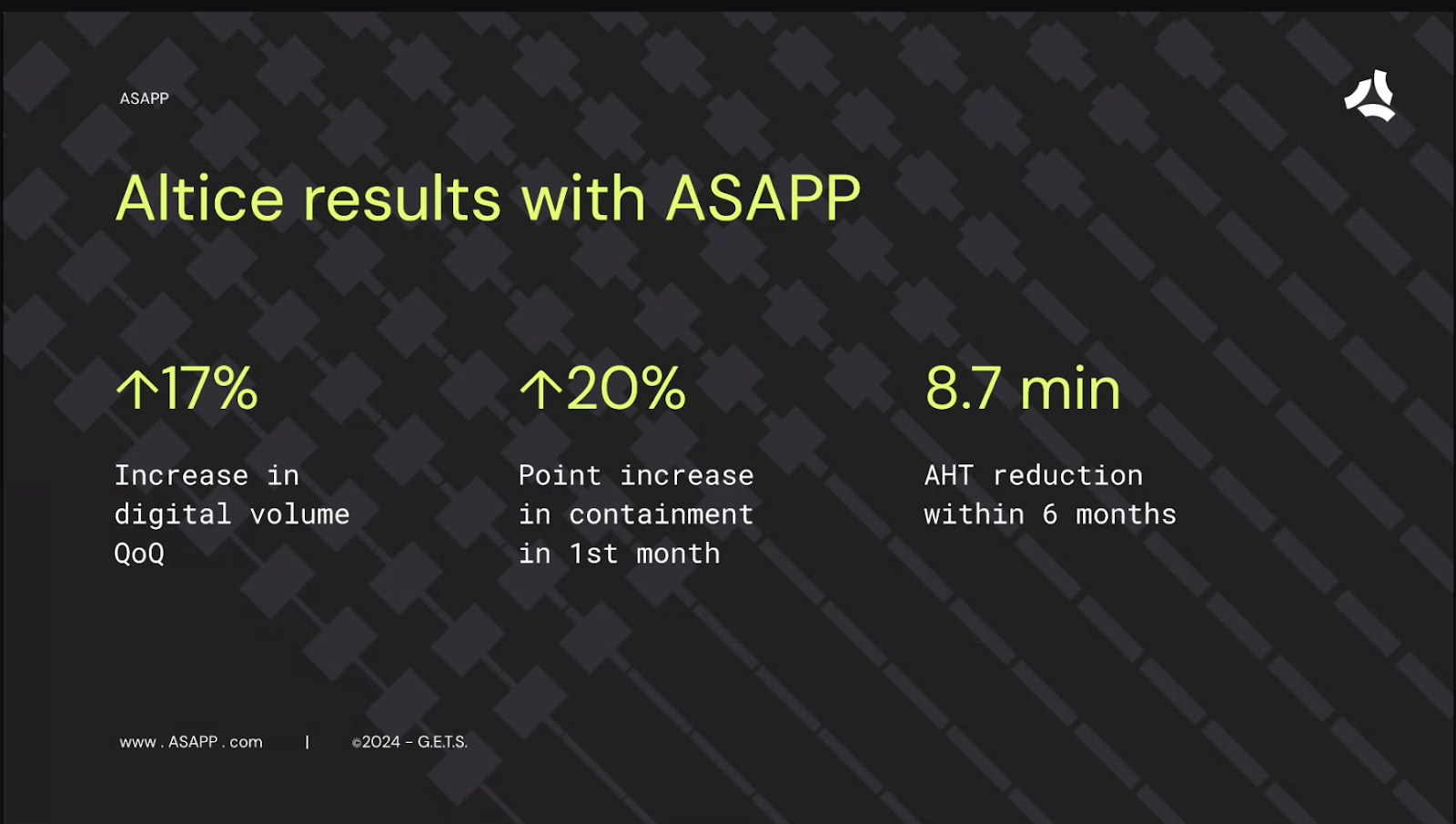
Nick: Yeah. It goes to the idea of focusing on the long-term gains. When you're optimizing and not pushing containment when it's not the right situation, that makes them come back to the channel, enjoy your brand, and have a delightful experience. So, thank you for sharing that.
Nick: But as I mentioned earlier, there's a lot of inertia. We know that moving a platform can be scary. Oftentimes, you're trying to manage timing considerations. So, I just want to say that we are mindful of the position you're in.
We've built it to allow you to get quick value and set up in under eight weeks. I know that’s a difficult thing for some other platforms to achieve, but you made the transition recently, Melissa. Justin, you've seen this a bunch of times. I’ll start with you, Justin. Do you have a few things in mind or some pointers on how to make these kinds of transitions easier, or even things people in our audience considering a platform switch should be thinking about?
Justin: Yeah, every situation's different, but thinking about some of the themes I’ve seen, the first piece of advice I would give is, at least in the beginning, skip the channels that aren't getting much use. I remember a couple of years ago when Google Business Messages was coming on the scene to compete with Apple Messages for Business, and everyone was excited about Facebook Messages as a support channel, and the same for Twitter DMs. If I look at 2024, those probably aren’t the areas getting the most attention. Google Messages is either turned off or soon to be defunct.
So I think about prioritization. If your customer base is in Latin America, WhatsApp should be your focus. If they’re primarily in the United States, maybe that’s not something you do on day one.
It’s about ordering priorities correctly and doing what will give you the biggest bang for your buck.
I would also say, as Melissa mentioned earlier regarding intents, you don’t necessarily need to replicate all your old flows when moving to a new platform. There’s definitely a place for classic deterministic flows. For something simple like, “What’s my bill balance?” you don’t need an LM to handle that. Sometimes, you may just want to navigate through a mini-system.
But as you look at your old deterministic flows, maybe you’ve got fifty in the old platform, but only need to bring over ten. For the rest, you can look to generative AI to handle those. Use that as an opportunity to save work and uplevel the experience.
The last thing would be embracing AI and machine learning for efficiency. Of course, I’m thinking about ASAPP’s platform here. There are many capabilities baked in, like giving agents a recommended response at the next turn of the conversation, or passing a question to a bot through automation.
There are opportunities like that, which are basically a training difference. It’s worth spending the time and giving agents the opportunity to use those tools so you can see that big efficiency bump as you transition.
Nick: Melissa, if I remember correctly, when we were engaging in that transition, timing was pretty important. I think we had a tight deadline. Could you tell us a bit more about that? And if you were giving advice to someone in the audience who’s in the same shoes you were in a year and a half ago, what kind of advice would you give them?
Melissa: Yeah, I mean, that’s one of the more nerve-wracking things when you're transitioning — making sure you hit that deadline because you’re cutting off your old platform, and moving on to the new one, with very little wiggle room for mistakes.
What was important to us as we thought about the planning behind it was making sure that, between ASAPP, my team on the digital side, and our IT teams, we were all aligned on that plan.
We were all aligned on the timing and what the level of effort would be to do that. Grounding ourselves first on what was truly MVP for this launch, and making sure we took into consideration if it was just a like-for-like? Or if there was room for a like-for-better? Do we have room for like-for-better? So those were some of the things we were looking at, and then what the use cases were if there was an opportunity to augment the platform a little bit more on day one.
But then when it came to actual execution and delivery, just really making sure that you’re running point and the partnership - there is the important piece again to highlight that. But they said one of the things that we appreciated was the extra level of effort that kinda went into them, like, really leaning in on that transition plan and making sure that we were able to meet that deadline. It came from our teams as well.
People wear many hats when it came to that last two to three weeks time period to make sure that we got all of our testing done and passed on time. And, I mean, happy to report, we launched with no major defects. There was one defect that we had post launch, and it was a small one. So it was really because of the collaboration across the teams.
Nick: I love to hear that. I mean, it really was a collaborative effort. I love hearing stories of customers saying that we're a good partner in helping with that. I think it touches on something that Justin mentioned earlier. It's not just the product and the features.
It's actually the partner that you get in the platform vendor.
I think it's a big part of how we think of things and how we support our customers.
Delivering a seamless digital customer experience is no small task—especially when existing platforms fall short. From limited automation capabilities to challenges with accessibility and support, organizations often encounter roadblocks that hinder both customer satisfaction and operational efficiency. When these gaps become too significant, making a platform transition becomes necessary.
In this first installment of our two-part series based on a discussion between Melissa Price, VP of Customer Experience for Digital Self-Serve at Altice and Justin Mulhearn, Head of Solutions Engineering at ASAPP, we explore the realities of switching messaging platforms. They share firsthand insights into the key pain points that led Altice to make a change, the biggest hurdles organizations face in these transitions, and how to approach the decision-making process strategically.
Read Part 2: Lessons learned from Altice’s successful digital messaging platform switch
* Minor edits have been made to the transcript for clarity and readability.
Nick (moderator): Melisa, you made the switch a little over a year ago. You were using another platform, and I understand Altice had some issues with it. I'd love to hear about some of the recurring frustrations you faced—or were there a handful of last straws that made you say, ‘Okay, we’ve known this was a problem, but now we have to make a change’?
Melissa: Yeah. Happy to share that. There are three areas specifically that I'll highlight.
One was around just the limited flexibility. Limited flexibility in terms of some of the insights that we were able to gather, and being able to go deeply enough to uncover the root of some of these opportunities, and how we would continue to grow in the chat space and deliver better experiences. And then how we present that to our customers and where we surface chat.
The other one was really around the access. Limited access in terms of being able to generate more flexibility for my team to then be able to make quick, continuous improvement efforts through the chat flows. And just making sure that we had the ability to really test and learn, and really make these real-time changes.
And then that last one, I would say, is just the engagement model.
If we were gonna start fresh with a new partner, we wanted to make sure that we had a better engagement model at the onset of it, and somebody who’s really looking at this as a partnership.
Nick: Justin, I know you've helped a bunch of customers make platform switches to ASAPP. Does this resonate? What else is common, or what are some of the other things you see in other platforms that hold them back from success?
Justin: Yeah, this definitely resonates. There are many inefficiencies and problems that we see as we’re working with these legacy platforms and programs. But to Melissa's point, oftentimes it's just about the account support. Sometimes it’s not even the technology.
But if your customer success team isn't there with you every single week, bringing you new features or really working with you on a continual basis, odds are the program’s not gonna reach its potential.
In terms of the programs themselves, this is both operational and technological.
I’ve seen a lot of programs out there that were never really optimized for digital and are still coming in with a voice mindset - If you have a program where you're taking chats, and it's a one-to-one concurrency like you had with voice, you’re basically getting no value out of the program.
But in a lot of programs, they tend to top out at a 1.2 to 1.3 level concurrency, and never really get beyond that. I think a lot of that does have to do with the underlying technology of the platforms themselves. From a basic perspective, you can have multiple concurrent conversations going on, but mental task switching between different subjects can be pretty difficult. So you really need the tooling and other support to help you shift rapidly back and forth between conversations as an agent.
Justin: And I’ll also say that, from the end customer's perspective, when I see these legacy programs where there’s no context being passed from a bot to a live agent, that always drives me nuts. That drives me nuts as a customer as well.
And then, oftentimes, I find that even when it gets to the live agent, the agents aren’t empowered to do the same things that they could do on the phone, which is just the most disappointing. “Hey, I just spent ten minutes getting to this point in the conversation only to find out that the agent can't actually help me.”
I think, Melissa, you were talking a little bit about that earlier this week. How have you dealt with that agent empowerment piece?
Melissa: I think context is so important.
As you look at every handoff part of the process, making sure that you're delivering it through the lens of where the customer came from, and having a common understanding of what may have been attempted before. That's an area we're continuing to work on, but not something that would be solved overnight. But, the context is so important, and then how that ties in not just to the chat platform, but also the tools that our agents would use, whether it be on the chat side or whether it be on the voice side.
Nick: Melissa, you’ve touched on some key aspects of what makes digital success possible. On the flip side, when you were considering making a switch to a new platform, what were the main things you were looking for in terms of both the engagement model and other key details to ensure success?
Melissa: We have a team that really is data focused, data led, and customer focused.
But I think when we’re looking at another partner for a chat solution, it was really important that the ideas and insights didn’t just come from my team, but also from whoever we’d be partnering with.
It was important to ensure that there were other insights brought forth proactively to help further understand different ways of thinking about the problems to solve. How do we uncover the root of some of these issues? What drivers may be behind containment, low containment, or poor experiences, as surfaced through NPS or other feedback from customers?
So, we were really trying to look at different angles to uncover opportunities and make sure we’re addressing the root causes. And then, partnering closely on finding a more optimized solution, based on key learnings from other clients or customers, with the potential to carry those insights into our work as well.
Nick: I know we talked earlier in the week about not just optimizing for digital, but even within digital, which I think really gets into how you best personalize and make the experience right for the customer in that specific moment and situation.
Melissa: Yeah, and if I could just share one specific example, it may seem small, but it can have an impact. When the customer is first interacting and engaging with us, initiating a chat, the intent is key. So, being able to uncover the right intent. We give customers the option to either select a list of canned intents based on our understanding of the context and entry point they may be coming from, or they have the free text option. But, it's about finding the right balance between how much we lean on the free text versus how much we’re continually updating and refining the canned intent list.
Those are things that we continue to cycle through to make sure we're delivering the best experience upfront, recognizing that when the customer’s trying to interact with us, we want to get them to the right place as soon as possible.
Watch the rest of the webinar.
At ASAPP we develop AI models to improve agent performance in the contact center. Many of these models directly assist contact center agents by automating parts of their workflow. For example, the automated responses generated by AutoCompose - part of our ASAPPMessaging platform - suggest to an agent what to say at a given point during a customer conversation. Agents often use our suggestions by clicking and sending them.
While usage of the suggestions is a great indicator of whether the agents like the features, we’re even more interested in the impact the automation has on performance metrics like agent handle time, concurrency, and throughput. These metrics are ultimately how we measure agent performance when evaluating the impact of a product like the AutoCompose capabilities of ASAPPMessaging, but these metrics can be affected by things beyond AutoCompose usage, like changes in customer intents or poorly-planned workforce management.
To isolate the impact of AutoCompose usage on agent efficiency, we prefer to measure the specific performance gains from each individual usage of AutoCompose. We do this by measuring the impact of automated responses on agent response time, because response time is more invariant to intent shifts and organizational effects than handle time, concurrency and throughput.
By doing this, we can further analyze:
Altogether, this enables us to be data-driven about how we improve models and develop new features to have maximum impact.
When we train AI models to automate responses for agents, the models look for patterns in the data that can predict what to say next based on past conversation language. So the easiest things for models to learn well are the types of messages that occur often and without much variation across different types of conversations, e.g. greetings and closings. Agents typically greet and end a conversation with a customer the same way, perhaps with some specificity based on the customer’s intent.

Most AI-driven automated response products will correctly suggest greeting and closing messages at the correct time in the conversation. This typically accounts for the first 10-20% of automated response usage rates. But when we evaluate the impact of automating those types of messages, we see that it’s minimal.
To understand this, let’s look at how we measure impact. We compare agents’ response times when using automated responses against their response times when not using automated responses. The difference in time is the impact—it’s the time savings we can credit to the automation.
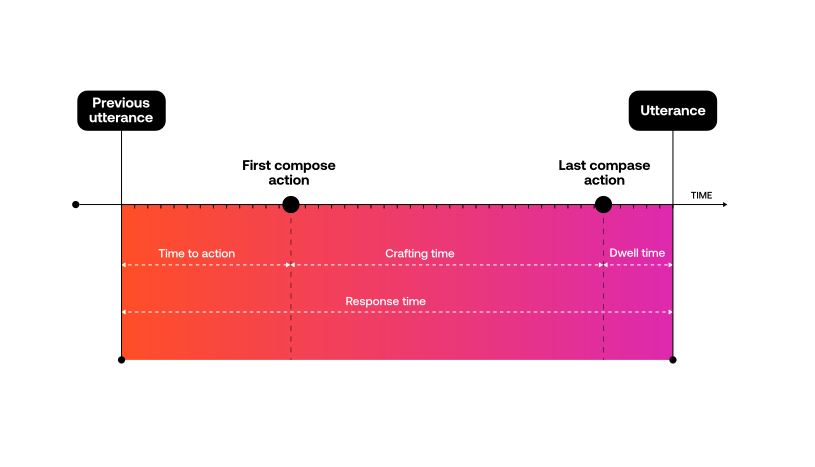
Without automation, agents are not manually typing greeting and closing messages for every conversation. Rather they’re copying and pasting from notepad or word documents containing their favorite messages. Agents are effective at this because they do it several times per conversation. They know exactly where their favorite messages are located, and they can quickly copy and paste them into their chat window. Each greeting or closing message might take an agent 2 seconds. When we automate those types of messages, all we are actually automating is the 2-second copy/paste. So when we see automation rates of 10-20%, we are likely only seeing a minimal impact on agent performance.
If automating the beginnings and endings of conversations is not that impactful, what is?

Automating the middle of the conversation is where response times are naturally slowest and where automation can yield the most agent performance impact.
- Heather Reed, Product Manager, ASAPP
The agent may not know exactly what to say next, requiring time to think or look up the right answers. It’s unlikely that the agent has a script readily available for copying or pasting. If they do, they are not nearly as efficient as they are with their frequently used greetings and closings.
Where it was easy for AI models to learn the beginnings and endings of conversations, because they most often occur the same way, the exact opposite is true of the middle parts of conversations. Often, this is where the most diversity in dialog occurs. Agents handle a variety of customer problems, and they solve them in a variety of ways. This results in extremely varied language throughout the middle parts of conversations, making it hard for AI models to predict what to say at the right time.

Whole interaction models are exactly what the research team at ASAPP specializes in developing. And it’s the reason that AutoCompose is so effective. If we look at AutoCompose usage rates throughout a conversation, we see that while there is a higher usage at the beginnings and endings of conversations, AutoCompose still automates over half of agent responses in between.
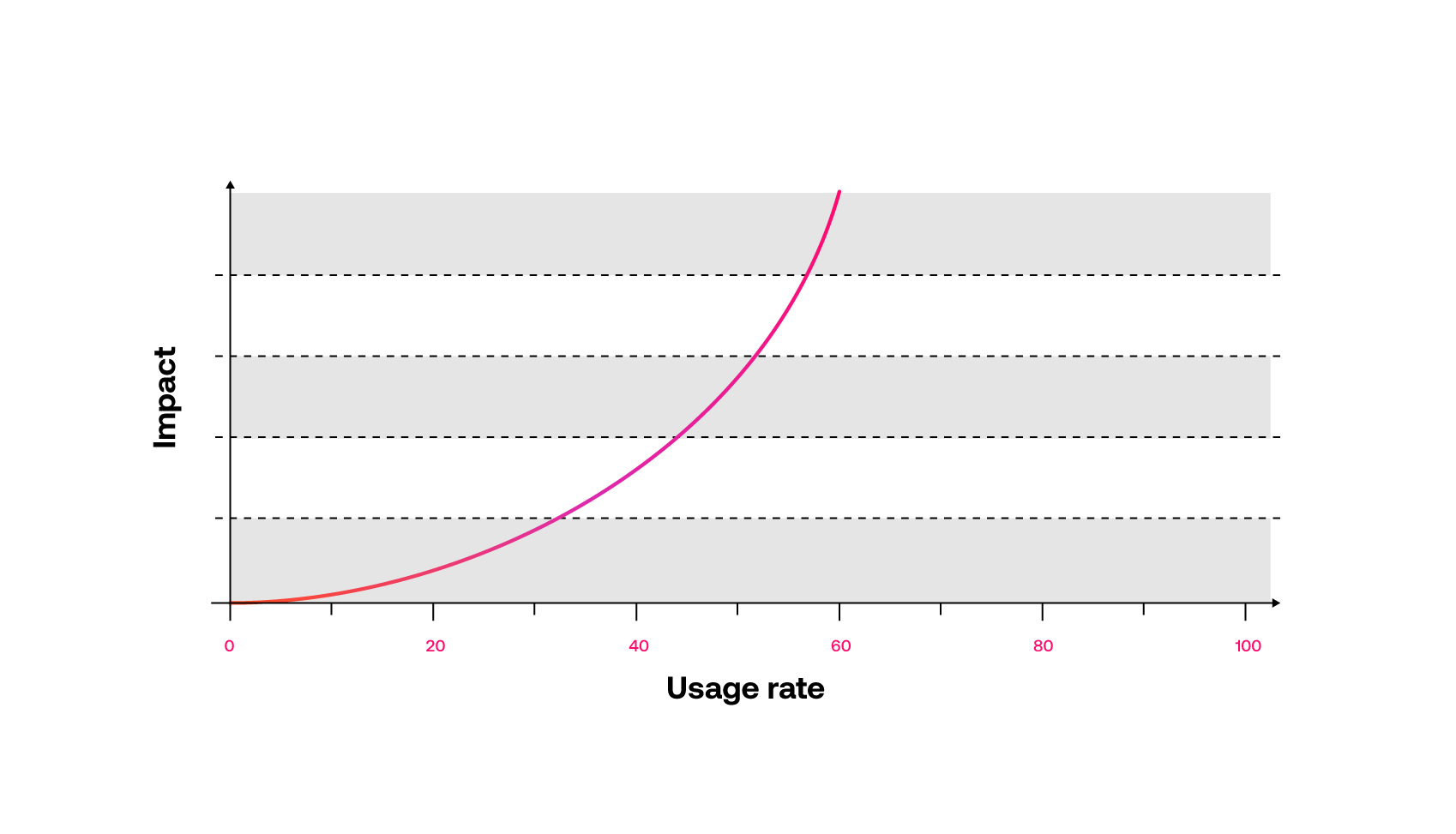
The low response times in the middle of conversations are where we see the biggest improvements in agent response time. It’s also where the biggest opportunities for improvements are realized.
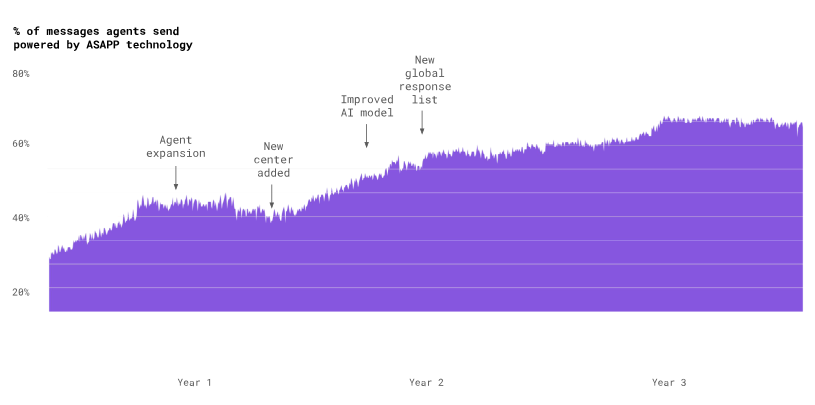
ASAPP’s current automated response rate is about 80%. It has taken a lot of model improvements, new features, and user-tested designs to get there. But now agents effectively use our automated responses in the messaging platform to reduce handle times by 25%, enabling an additional 15% of agent concurrency, for a combined improvement in throughput of 53%. The AI model continues to get better with use, improving suggestions, and becoming more useful to agents and customers.
Talk of Generative AI transforming contact centers is everywhere. From boardrooms of the world’s largest enterprises to middle management and frontline agents, there’s a near-universal consensus: the impact will be massive. Yet, the path from today’s reality to that future vision is full of challenges.
The key to bringing customer-facing Gen AI to production today lies in a human-in-the-loop workflow, where AI agents consult human advisors whenever needed—just as frontline agents might seek guidance from a tier 2 agent or supervisor. This approach both unlocks benefit today while providing a self-learning mechanism driving greater automation in the future.
We've spilled our fair share of digital ink on how Generative AI marks a step change in automation and how it will revolutionize the contact center. But let's take a moment to acknowledge the key challenges that must be overcome to realize this vision.
AI's ability to generate human-like responses makes it powerful, but this capability comes with risks. Gen AI systems are inherently probabilistic, meaning they can occasionally hallucinate—providing incorrect or misleading information. These mistakes, if unchecked, can erode customer trust at best and damage a brand at worst.
When evaluating a Gen AI system, the critical question to ask is not “will the system hallucinate?” It will. The critical question is, “will hallucinated output get sent to my customers?”
With GenerativeAgent® every outgoing message is evaluated by an output safety module that, among other things, checks for hallucinations. If a possible hallucination is detected, the message is assigned to a human-in-the-loop advisor for review. This safeguard prevents the dissemination of erroneous information while allowing the virtual agent to maintain control of the interaction.
In systems without this kind of human oversight, mistakes could lead to escalations or, worse, unresolved customer issues, or worse yet, damaged customer relationships or brand. By integrating a human-in-the-loop workflow, businesses can mitigate the risks inherent to this technology while maximizing the business benefits it offers.
Deploying customer-facing Gen AI in a contact center doesn’t mean relinquishing all decision-making power to the AI. There are situations where human judgment is crucial, particularly when the stakes are high for both the business and the customer.
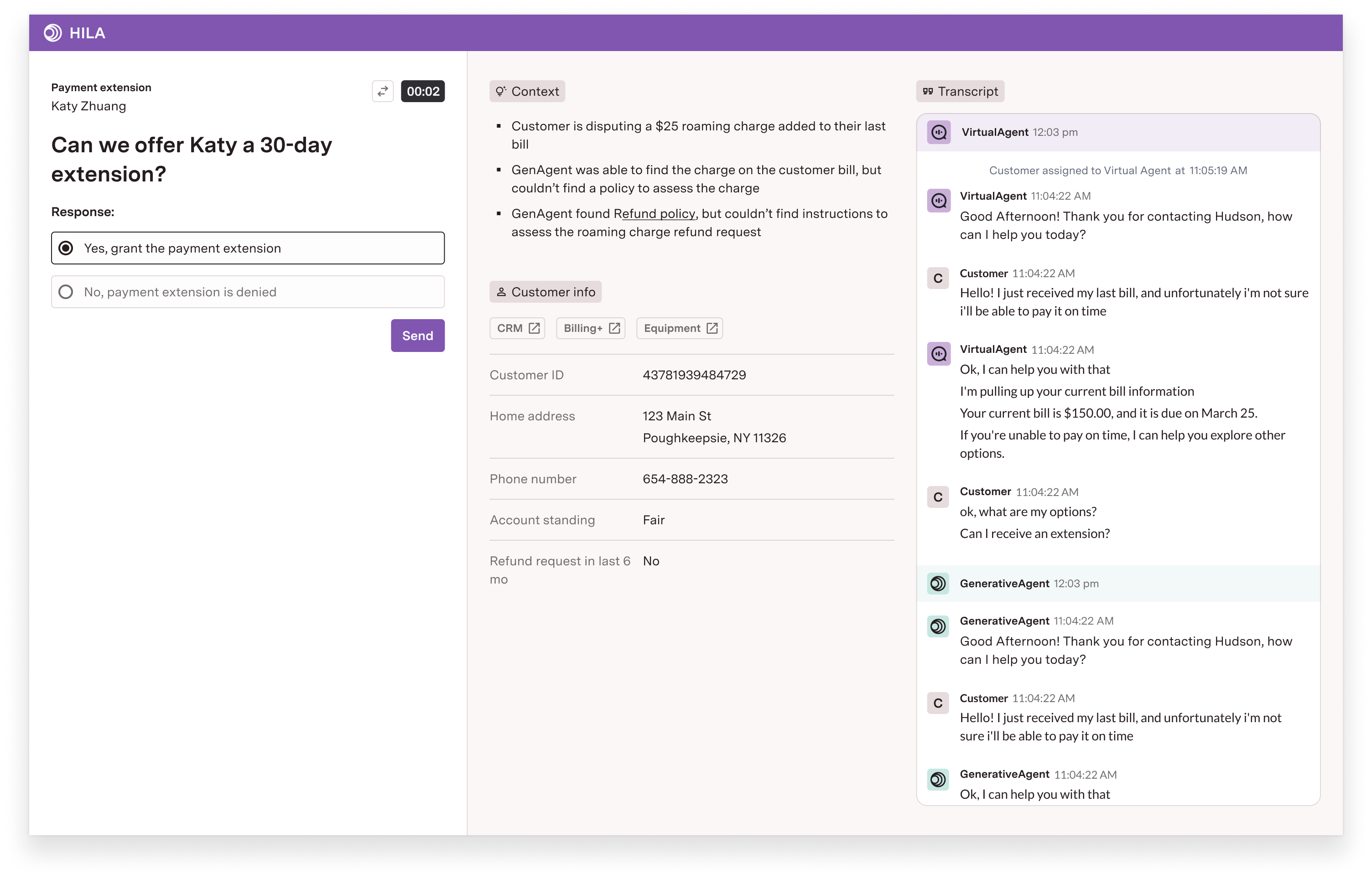
Take, for example, a customer requesting a payment extension or a final review of their loan application. These are pivotal decisions that involve weighing factors like risk, compliance, and customer loyalty. While a Gen AI agent can automate much of the interaction leading up to these moments, the final decision still requires human judgment.
With a human-in-the-loop framework, this is no longer a limitation. The AI agent can seamlessly consult an advisor for approval while maintaining control of the customer interaction, much like a Tier 1 agent consulting a supervisor. This approach provides flexibility—automating what can be automated while reserving human intervention for critical decisions. For the business, this boosts automation rates, reduces escalations, and empowers advisors to focus on high-impact judgments where their expertise is essential.
No matter how advanced Gen AI virtual agents become, some customers will still ask to speak with a live agent—at least for now. Of all the challenges outlined, this one is the most intractable, driven by customer habits and expectations rather than technology or process.
Human-in-the-loop offers a smart alternative. Rather than instantly escalating to a live agent when requested, the Gen AI agent could inform the customer of the wait time and propose a review by a human advisor in the meantime. If the advisor can help the Gen AI agent resolve the issue quickly, the escalation can be avoided entirely—delivering a faster resolution without disrupting the flow of the interaction.
While not every customer will accept this deflection, it can significantly reduce this type of escalation and address one of the toughest barriers to full automation.
Many systems that agents rely on today lack APIs, putting a large volume of customer issues beyond the reach of automation.
Rather than dismissing these cases, a human-in-the-loop advisor can bridge this gap—handling tasks on behalf of the Gen AI agent in systems that lack APIs.
The value extends beyond expanding automation. It highlights areas where developing APIs or streamlining access to legacy systems could deliver significant ROI. What was once hard to justify becomes clear: introducing new APIs directly reduces the advisor hours spent compensating for their absence.
Generative AI is poised to reshape the contact center, but unlocking its full potential requires a tightly integrated human-in-the-loop workflow. This framework ensures that customer-facing Gen AI is ready for production today while providing a self-learning mechanism driving to greater automation gains tomorrow.
While AI technology continues to advance, the role of human advisors is not diminishing—it’s evolving. By embracing this collaboration, businesses can strike the right balance between automation and human judgment, leading to more efficient operations and better customer experiences.
In future posts on human-in-the-loop, we’ll dive deeper into how to enhance collaboration between AI and human agents, and explore the evolving role of humans in AI-driven contact centers.

%2520(2).png)



