Article
Video

Suwon Shon, PhD is Senior Speech Scientist at ASAPP. He received B.S and Ph. D on electrical engineering from Korea University. He was a post-doctoral associate and research scientist at Massachusetts Institute of Technology (MIT) Computer Science and Artificial Intelligence Laboratory by leading speaker and language recognition project. His research interests include machine learning technologies for speech signal processing focusing on spoken language understanding.
Progress on speech processing has benefited from shared datasets and benchmarks. Historically, these have focused on automatic speech recognition (ASR), speaker identification, or other lower-level tasks. However, “higher-level” spoken language understanding (SLU) tasks have received less attention and resources in the speech community. There are numerous tasks at varying linguistic levels that have been benchmarked extensively for text input by the natural language processing (NLP) community – named entity recognition, parsing, sentiment analysis, entailment, summarization, and so on – but they have not been as thoroughly addressed for speech input.
Consequently, SLU is at the intersection of speech and NLP fields but was not addressed seriously from either side. We think that the biggest reason for this disconnect is due to a lack of an appropriate benchmark dataset. This lack makes performance comparisons very difficult and raises the barriers of entry into this field. A high quality benchmark would allow both the speech and NLP community to address open research questions about SLU—such as which tasks can be addressed well by pipeline ASR+NLP approaches, and which applications benefit from having end to end or joint modeling. And, for the latter kind of tasks, how to best extract the needed speech information.

For conversational AI to advance, the broader scientific community must be able to work together and explore with easily accessible state-of-the-art baselines for fair performance comparisons.
We believe that for conversational AI to advance, the broader scientific community must be able to work together and explore with easily accessible state-of-the-art baselines for fair performance comparisons. A present lack of benchmarks of this kind is our main motivation in establishing the SLUE benchmark and its suite.
We are launching the first benchmark which considers ASR, NER, and SLU with a particular emphasis on low-resource SLU. For this benchmark, we contribute the following:
SLUE covers 2 SLU tasks (NER and SA) + ASR tasks. All evaluation in this benchmark starts with the speech as input whether it is a pipeline approach (ASR+NLP model) or end-to-end model that predicts results directly from speech.
The provided SLUE benchmark suite covers for downloading dataset, training state-of-the-art baselines and evaluation with high-quality annotation. In the website, we provide the online leaderboard to follow the up-to-date performance and we strongly believe that the SLUE benchmark makes SLU tasks much more easily accessible and researchers can focus on problem-solving.
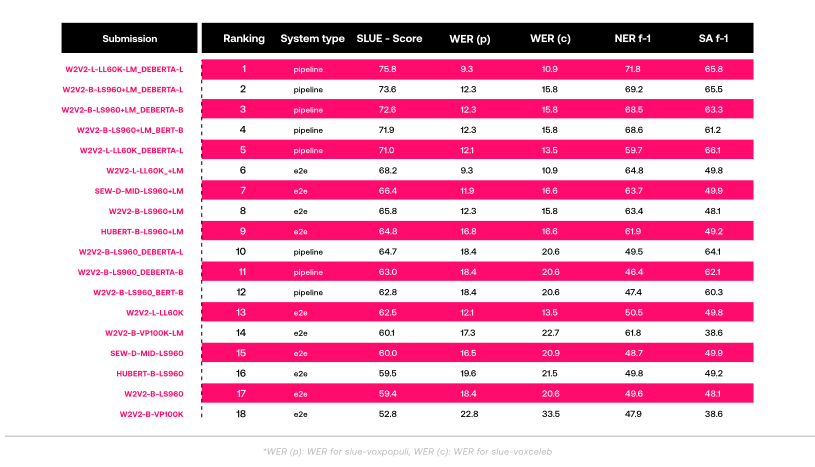
Current leaderboard of the SLUE benchmark
Recent SLU-related benchmarks have been proposed with similar motivations to SLUE. However, those benchmarks cannot perform as comprehensively as SLUE due to the following reasons:
SLUE provides a comprehensive comparison between models without those shortcomings. An expected contribution to the SLUE benchmark would
Motivated by the growing interest in SLU tasks and recent progress on pre-trained representations, we have proposed a new benchmark suite consisting of newly annotated fine-tuning and evaluation sets, and have provided annotations and baselines for new NER, sentiment, and ASR evaluations. For the initial study of the SLUE benchmark, we evaluated numerous baseline systems using current state-of-the-art speech and NLP models.
This work is open to all researchers in the multidisciplinary community. We welcome similar research efforts focused on low-resource SLU, so we can continue to expand this benchmark suite with more tests and data. To contribute or expand on our open-source dataset, please email or get in touch with us at sshon@asapp.com.
The future of real-time speech sentiment analysis shows promise in offering new capabilities for organizations seeking to understand how customers feel about the quality of service received across customer service interactions. By understanding customer sentiment the moment customers say it, organizations are equipped with the intelligence to make nimble changes in service. To date, customer feedback surveys fulfilled this purpose but present with some known limitations.
In addition to the low percentage of customers who fill out surveys, customer feedback surveys have a problem with bias: customers are more likely to respond to a survey when having either a positive or negative experience, thus heavily skewing results to positive and negative feedback. With low response rates and biased results, it’s hard to argue that surveys provide a complete picture of the customer experience. Helping fill out this picture, future speech sentiment analysis capabilities offer another way for organizations to evaluate all of the interactions a customer has.
By collecting more information from every call (and not just a few polarized survey responses), speech sentiment could be a way to reduce bias and provide a more comprehensive measure of the customer experience. Future capabilities, which can measure real-time attitude and opinion regarding the service customers receive, can equip organizations with intelligence to make swift shifts in agent coaching or experience design. As more contact center agents work from home, access to live sentiment insight could be a great way for supervisors to support agents on a moment’s whim without needing to be in the same office.
Current methods in speech sentiment analysis are bringing us closer to realizing these real-time sentiment analysis capabilities, but several research hurdles remain in acquiring the right dataset to train these models. Medhat et. al 2014 illustrate how current NLP sentiment data comes in the form of written text reviews, but this is not the right kind of data needed for speech analysis of conversational recordings. Even when audio data is available, it often arrives in limited scripted conversations repeated from a single actor or monologue–which is insufficient for sentiment analysis on natural conversations.
As we work to advance the state of the art in speech sentiment analysis, new ASAPP research presented at Interspeech 2021 is making progress in lowering these barriers.
While ASAPP’s automatic speech recognition (ASR) system is a leader in speech-to-text performance, conventional methods of using cascading ASR and text-based natural language processing (NLP) sentiment analysis systems have several drawbacks.
Large language models trained on text-based examples for sentiment analysis show a large drop in accuracy when applied to transcribed speech. Why? We speak differently than how we write. Spoken language and written language lie in different domains, so the language model trained on written language (e.g. BERT was trained using BooksCorpus and Wikipedia) does not perform well on spoken language input.

Furthermore, abstract concepts such as sarcasm, disparagement, doubt, suspicion, yelling, or intonation further complicate the complexity of speech sentiment recognition over an already challenging task of text-based sentiment analysis. Such systems lose rich acoustic/prosodic information which is critical to understanding spoken language (such as changes in pitch, intensity, raspy voice, speed, etc).
Speech annotation for training sentiment analysis models has been offered as a way to overcome this obstacle for controlled environments [Chen et. al, 2020], but is costly in collection efforts. While publicly available text can be found virtually everywhere–from social media to English literature, acquiring conversational speech with the proper annotations is harder given limited open-source availability. And, unlike sentiment-annotated text, speech annotations have to require more time listening to the speech.
Leveraging pre-training neural networks is a popular way to save the annotation resource on downstream tasks. In the field of NLP, great advances have been made through pre-training task-agnostic language models without any supervision, e.g. BERT. Similarly, in the study of Spoken Language Understanding (SLU), pre-training approaches were proposed in combination with ASR or acoustic classification modules to improve SLU performance under limited resources.
The aforementioned pre-training approaches only focus on how to pre-train the acoustic model effectively with the assumption that if a model is pre-trained to recognize words or phonemes, the fine-tuning result of downstream tasks will be improved. However, they did not consider transferring information from the language model that had already been trained with a lot of written text data to the conversational domain.
We propose the use of powerful pre-trained language models to transfer more abstract knowledge from the written text-domain to speech sentiment analysis. Specifically, we leverage pre-trained and fine-tuned BERT models to generate pseudo labels to train a model for the end-to-end (E2E) speech sentiment analysis system in a semi-supervised way.

For the E2E sentiment analysis system, a pre-trained ASR encoder is needed to prevent overfitting and encode speech context efficiently. To transfer the knowledge from the text domain, we generated pseudo sentiment labels from either ASR transcript or ground truth human transcript. The pseudo labels can be used to pre-train the sentiment classifier in the semi-supervised training phase. In the fine-tuning phase, the sentiment classifier can be trained with any speech sentiment dataset we want to use. Target domain matched speech sentiment dataset would give the best result in this phase. We verified our proposed approach using a large scale Switchboard sentiment dataset [Chen et al. 2020].
Transfer learning between spoken and written language domains was not actively addressed before. This work found that pseudo sentiment labels obtained from a pre-trained model trained in the written text-domain can transfer the general sentiment knowledge into the spoken language domain using a semi-supervised training framework. This means that we can train the network more efficiently with less human supervision.
Suwon Shon, PhD
Transfer learning between spoken and written language domains was not actively addressed before. This work found that pseudo sentiment labels obtained from a pre-trained model trained in the written text-domain can transfer the general sentiment knowledge into the spoken language domain using a semi-supervised training framework.

This means that we can train the network more efficiently with less human supervision. From the experiment in Figure 3 we can save about 65% (30h vs. 86h) of human sentiment annotation using our pseudo label-based semi-supervised training approach. On the other hand, this also means that we can boost the performance of sentiment analysis when we use the same amount of sentiment annotated training set. We observe that the best system showed about 20% improvement on unweighted F1 score (57.63%) on the evaluation set compared to the baseline (48.16%).

Lastly, we observed that using ASR transcripts for pseudo labels gives a slight performance degradation, but still shows better performance than the baseline. This result allows us to use a huge unlabeled speech for a semi-supervised training framework without any human supervision.








.jpg)
.jpg)
.jpg)
