Table of Contents

A lot has been written lately about the importance of accuracy in speech-to-text transcription. It’s the key to unlocking value from the phone calls between your agents and your customers. For technology evaluators, it’s increasingly difficult to cut through the accuracy rates being marketed by vendors—from the larger players like Google and Amazon to smaller niche providers. How do you determine the best transcription engine for your organization to unlock the value of transcription?
The reality is that there is no one speech transcription model to rule them all. How do we know? We tried them.
In our own testing some models performed extremely well in industry benchmarks. But then they failed to reproduce even close to the same results when put into production contact center environments.
Benchmarks like Librispeech use a standardized set of audio files which speech engineers optimize for on many different dimensions (vocabulary, audio type, accents, etc). This is why we see WERs in the <2% range. These models are now outperforming the human ear (4% WER) on the same data which is an incredible feat of engineering. Doing well on industry benchmarks is impressive—but what evaluators really need to know is how these models perform in their real-world environment.
What we’ve found in our own testing is that most off-the-shelf Automatic Speech Recognition (ASR) models struggle with different contact center telephony environments and the business specific terminology used within those conversations. Before ASAPP, many of our customers were able to get transcription live after months of integration and even utilized domain specific ASRs, but only saw accuracy rates in the area of 70%, nudging closer to 80% only in the most ideal conditions. That is certainly a notch above where it was 5 or 10 years ago, but most companies still don’t transcribe 100% of phone calls. Why? Because they don’t expect to get enough value to justify the cost.
So how much value is there in a higher real-world accuracy rate?

The words that are missed in the gap between 80% accuracy and 90% accuracy are often the ones that matter most. They’re the words that are specific to the business and are critical to unlocking value.
Austin Meyer
More than you might imagine. Words that are missed are often the most important ones—specific to the business and are critical to unlocking value. These would be things like:
- Company names (AT&T, Asurion, Airbnb)
- Product and promotion names (Galaxy S12, MLB League Pass, Marriott Bonvoy Card)
- People’s names, emails and addresses
- Long numbers such as serial numbers and account numbers
- Dollar amounts and and dates
To illustrate this point, let’s look at a sample of 10,000 hours of transcribed audio from a typical contact center. There are roughly 30,000 unique words within those transcripts, yet the system only needs to recognize 241 of the most frequently used words to get 80% accuracy. Those are largely words like “the”, “you”, “to”, “what”, and so on.
To get to 90% accuracy, the system needs to correctly transcribe the next 324 most frequently used words, and even more for every additional percent. These are often words that are unique to your business—the words that really matter.
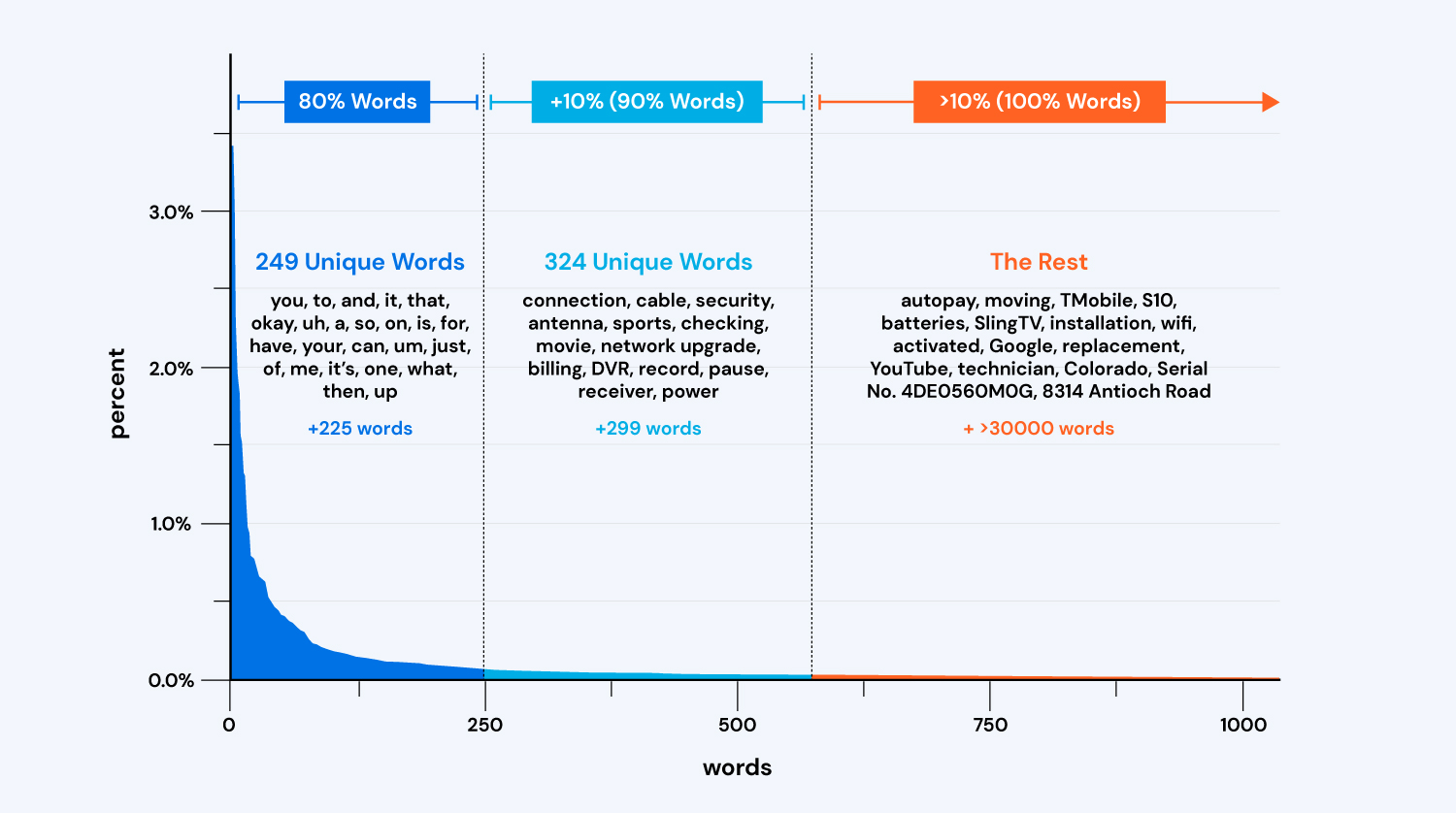
Context also impacts accuracy and meaning. If someone says, “Which Galaxy is that?”, depending on the context, they could be talking about a Samsung phone or a collection of stars and planets. This context will often impact the spelling and capitalization of many important words.
Taking this even further, if someone says, “my Galaxy is broken”, but they don’t mention which model they have, anyone analyzing those transcripts to determine which phone models are problematic won’t know unless that transcript is tied to additional data about that customer. The effort of manuallying integrating transcripts to other datasets that contain important context dramatically increases the cost of getting value from transcription.
When accuracy doesn’t rise above 80% in production and critical context is missing, you get limited value from your data– nothing more than simple analytics like high level topic/intent categorization, maybe tone, basic keywords, and questionable sentiment scores. That’s not enough to significantly impact the customer experience or the bottom line.
It’s no wonder companies can’t justify transcribing 100% of their calls despite the fact that many of them know there is rich data there.
The key to mining the rich data that’s available in your customer conversations—and to getting real value from transcribing every word of every call is threefold:
- Make sure you have an ASR model that’s custom tuned and continuously adapts to the lexicon of your business.
- Connect your transcripts to as much contextual metadata as possible.
- Have readily accessible tools to analyze data and act on insights in ways that create significant impact for your business—both immediately and long term.
ASAPP answers that call. When you work with us you’ll get a custom ASR model trained on your data to transcribe conversation in real time, and improve with every call. Our AI-driven platform will deliver immediate business value through an array of CX-focused capabilities, fed by customer conversations and relevant data from other systems. Plus, it provides a wealth of voice of the customer data that can be used across your business. When you see your model in action and the tremendous value you get with our platform, it makes a lot more sense to transcribe every word of every call. Interested? Send us a note at ask@asapp.com and we’ll be happy to show you how it’s done.


