Table of Contents

Named entity recognition (NER) aims to identify and categorize spans of text into entity classes, such as people, organizations, dates, product names, and locations. As a core language understanding task, NER powers numerous high-impact applications including search, question answering, and recommendation.
At ASAPP, we employ NER to understand customer needs, such as upgrading a plan to a specific package, making an appointment on a specific date, or troubleshooting a particular device. We then highlight these business-related entities for agents, making it easier for them to recognize and interact with key information.
Typically, training a state-of-the-art NER model requires a large amount of annotated data, which can be expensive and take weeks to obtain. However, a much more rapid response is demanded by many business use cases. For example, you can’t afford a weeks-long wait when dealing with emerging entities like those related to an unexpected natural disaster or a fast-changing pandemic such as with COVID-19.
My colleague PostDoc researcher Arzoo Katiyar and I solve this challenge using few-shot learning techniques. In few-shot learning, only a few labeled examples (typically one to five examples) are needed for the ML algorithm to train. We applied this technique to NER by transferring the knowledge from existing NER annotations from public NER datasets which only focus on entities in the general domain to each new target entity class. This is achieved by learning a similarity function between a target word and an entity class.

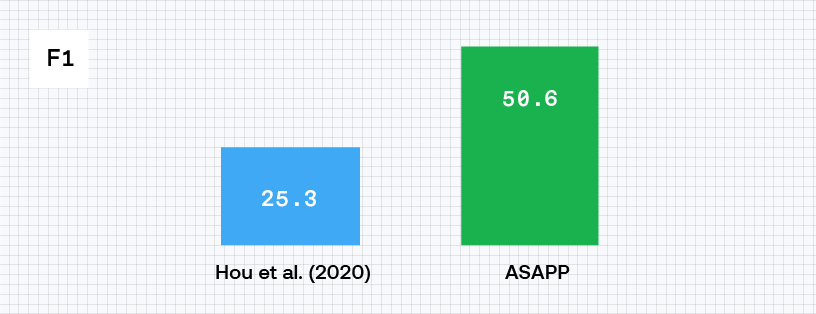
When we apply structured nearest neighbor learning techniques to named entity recognition (NER) we’re able to double performance, as shared in our paper published at EMNLP 2020. This translates to higher accuracy—and better customer experiences.
Yi Yang, PhD
Few-shot learning techniques have been applied to language understanding tasks in the past. However, compared to the reasonable results obtained by the state-of-the-art few-shot text classification systems (e.g., classify a web page into a topic such as Troubleshooting, Billing, or Accounts), prior state-of-the-art NER performance was far from satisfactory.
Moreover, existing few-shot learning techniques typically require the training and deployment of a fresh model, in addition to the existing NER system, which can be costly and tedious.
We identified two issues with adopting the existing few-shot learning techniques for NER. First, the existing techniques assume that each class has a single semantic meaning. NER adds a special class called ‘Outside’, which means it is not one of the entities that this specific model is looking for. If a word is labeled as ‘Outside’, it means that it doesn’t fit in the current set of entities, however, it can still be a valid entity in another dataset. This suggests that the ‘Outside’ class corresponds to multiple semantic meanings.
Second, they fail to model label-label dependencies, e.g., given the phrase “ASAPP Inc”, knowing that “ASAPP” is labeled as ‘Organization’ would suggest that “Inc” is also likely to be labeled as ‘Organization’.
Our approach is to address the issues with nearest-neighbor learning and structured decoding techniques, as detailed in our paper published at EMNLP 2020.
By combining the techniques, we are able to create a novel few-shot NER system that outperforms the previous state-of-the-art system by doubling the F1 score (standard evaluation metric for NER, similar to accuracy) from 25% to 50%. Thanks to the flexibility of the nearest neighbor technique, the system can work on top of the conventionally deployed NER model, which eliminates the expensive process of model retraining and redeployment.
The work reflects the innovation principle of our world-class research team at ASAPP—identify the most challenging problems in customer experience, and push hard to overcome the challenge without worrying about the confines of current limits.


