Table of Contents

We've all heard how good AI voices can sound. The demos are stunning—voices you'd swear were real—but rarely the experience when you actually call an automated system in production. The gap between voices in a demo and what they deliver in a real interaction is enormous. At ASAPP, we have moved past the idea of voice-as-an-output and view it as a holistic customer experience. We focus on the deep orchestration and next-generation architectures between the thought and the sound. For leading global enterprises, this is where trust is either engineered or lost.
The pace of innovation in voice AI is now measured in weeks. Our research is dedicated to exploring the absolute frontier of what is possible, working with the latest models from pioneers long before they hit the mainstream, and operationalizing for enterprise customers.
The "voice ensemble": Orchestration and calibration
We don’t just “deploy” a voice; we calibrate it for specific, high-stakes industry archetypes. A voice is rarely optimized for the specific needs of an enterprise. This is where our Voice Ensemble and the associated customization and calibration process become a critical differentiator. We act as a provider-agnostic orchestration layer, creating or curating the best-performing voices and models from across the frontier for each industry. Then, our customers can select, from the curated catalog, the best voices that reflect their brand and further calibrate them to create their own ensemble of voices that serves their customers best rather than having them locked into a single model provider’s library of voices. Examples include:
Airlines: the Efficient Concierge: For global carriers, we calibrate for proactive, high-speed delivery. When a traveler is navigating a missed connection in a noisy terminal, the agent must project "in-control" competence, handling rebookings with zero friction with the right touch of empathy.
Fintech: the High-Precision Specialist: For global banks, we calibrate for authority and details. The voice must project absolute reliability when discussing sensitive 401(k) transfers or fraud alerts.
Healthcare: the Empathetic Caregiver: For major insurers, we calibrate for warmth and a reassuring prosody. In high-stress moments, like a patient checking coverage for an urgent procedure, the cadence and pausing of the voice—its sense of "breath"—must signal genuine.

Interaction tuning: Engineering the space between words
Selecting and calibrating a voice is only part of the equation. A beautifully calibrated voice paired with a system that goes silent while it thinks will still break the interaction.
Our architecture separates the talker from reasoning. While the reasoning layer executes workflows, calls functions, and manages state in the background, the talker maintains the conversation: managing caller expectations, bridging processing time naturally, and delivering information at a pace the caller can absorb. Through workflow configuration and context management, enterprises can guide the nature of these interactions: how the agent progresses through a multi-step procedure, what the caller hears at each stage, and how the experience adapts as context accumulates. These are not afterthoughts; they are configuration decisions that directly shape whether the voice sounds as good in production as it does in the lab.
Navigating complexity: The mechanical polish
A voice is only as competent as its smallest unit of speech. Many "human-like" models fail when they encounter the technical reality of enterprise data. If a virtual agent stumbles over a 10-digit policy number or mispronounces a flight confirmation code, the thread of trust snaps.
We focus on the Mechanical Polish of the interaction:
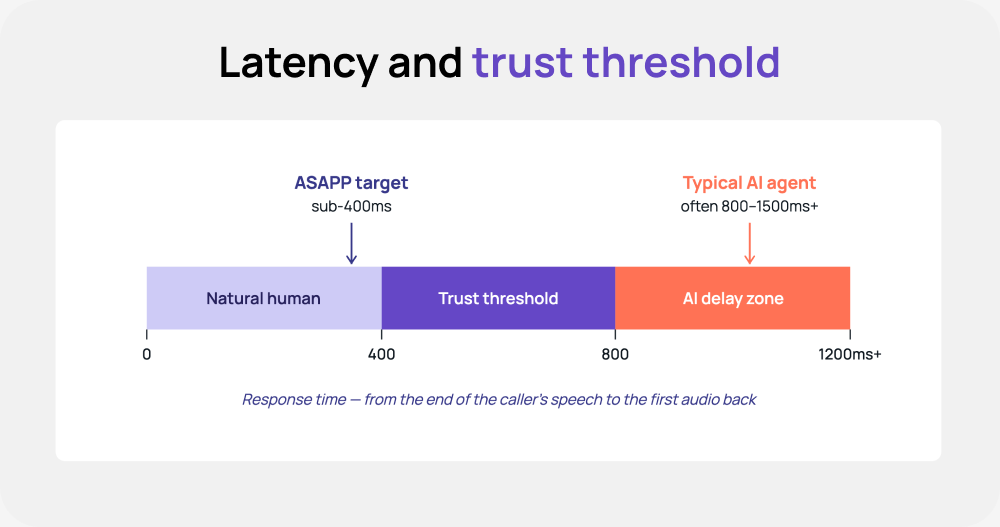
VAD Control and Latency Optimization: Precise control over Voice Activity Detection (VAD) is essential for fluid conversations, enabling highly responsive interruption and minimizing talk-over. Simultaneously, we implement aggressive end-to-end latency management to deliver audio responses that consistently remain closer to human’s sub-400ms, making the conversation feel natural and trustworthy.
ASR Robustness and Background Noise Handling: Our systems employ specialized Automatic Speech Recognition (ASR) models calibrated for high-stakes enterprise terminology and engineered for robustness against real-world chaos, ensuring perfect comprehension even amidst high background noise.
Pronunciation Dictionaries: We support consistent, perfect pronunciation of industry-specific jargon and complex data strings—like Alpha-Numeric confirmation codes or medical terminology—via custom dictionaries for every enterprise partner.
Intelligent Intersections: We use natural fillers and acknowledgments to bridge the milliseconds of back-end processing, ensuring the conversation feels like a continuous human interaction rather than a series of disjointed API calls.
Robustness: Benchmarking against the human standard
We believe that "vibes" are not a strategy.
In our labs, we move beyond subjective evaluation to a data-driven framework that benchmarks our agents against live human performance across three critical dimensions: technical resilience, functional trust, and task efficiency.
Robustness in chaos: Performance beyond the lab
True robustness is defined by how an agent performs under the degraded conditions of the real world—not just in a clean laboratory environment. We measure robustness in chaos by subjecting our models to high-stress environments, including noisy terminal audio and telephony-grade compression. Our goal is to ensure that even in these compromised states, the agent maintains a sub-400ms response speed, effectively eliminating the "AI delay" and keeping the interaction grounded in natural human rhythms.
Functional trust: Deterministic guardrails
Trust is a product of predictability. We implement deterministic guardrails that enforce brand-safe behavior and policy compliance in real-time. Unlike traditional architectures where safety checks add hundreds of milliseconds of latency, our guardrails are integrated directly into the neural loop. This allows us to maximize the Trust & Confidence metric—ensuring users feel secure sharing sensitive data—without compromising our move toward the human-level threshold.
Technical telemetry: Quantifying the interaction gap
We measure mechanical performance using a precise telemetry stack that maps directly to the human conversational experience. By tracking these metrics in real-time, we ensure the agent remains within the "trust zone" of natural dialogue.
- Latency Thresholds (TTFA & P95): We target a median Time-to-First-Audio (TTFA) to minimize cognitive load. While we ensure P95 latency stays below the 800ms natural "trust threshold," our core architecture is optimized for a sub-400ms benchmark.
- Interruption Accuracy: We measure User Interruption Rate and Barge-in Stop Latency to ensure the agent respects social cues, stopping instantly to avoid awkward "talk-overs."
- Precision in Data Handling: Leveraging our proprietary quality framework, we stress-test the agent’s ability to capture entity-heavy information (like alphanumeric account codes) with near-perfect accuracy.
The Human-Level Threshold: Task Efficiency
The ultimate benchmark is whether the experience is as good as, or better than, a live human representative. We measure this through structured challenger testing—placing voice variants head-to-head on identical enterprise workflows. We evaluate success based on Task Efficiency and Clarity, ensuring that when a user completes a complex inquiry without ever being reminded they are talking to an AI, we have successfully defined the frontier of spoken automation.
Conclusion: The future voice automation
The next era is not about "better voices" — it is about the holistic customer experience with voice automation.
We are already engineering the next generation through native Speech-to-Speech (S2S) architectures, collapsing the traditional cascade into a single, unified neural loop to achieve human-level latency and emotional nuance.
But the architecture is only as good as the experience it delivers. Voice selection, calibration, interaction tuning, mechanical polish, and rigorous benchmarking. These are the balanced factors that close the gap between the demo and the production experience.
In the world of spoken automation, the winner isn't the one with the prettiest voice. It's the one who builds the most trusted customer experience.
.jpg)

