Table of Contents

In the enterprise AI landscape, "safety" is often treated as a static checkbox—a single audit or penetration test performed before a model or an agent is shipped. But as adversarial techniques evolve from simple prompt injections to complex, multi-turn "jailbreaks," a one-time defense is a liability.
ASAPP is proud to announce a new capability: Continuous Red Teaming. By integrating Promptfoo directly into our model evaluation framework, we are ensuring that our safety layers are not just active, but proactively hardened against the latest emerging threats.
Agentic defense: Fighting AI with AI
Most safety filters are reactive, relying on static "blocked word" lists. ASAPP’s approach is aggressively proactive. Using Promptfoo’s specialized Red Team Agents, we subject our models and agents to an adversarial gauntlet. These agents don't just send random texts; they use high-reasoning uncensored models to "think" like an attacker, iteratively probing for weaknesses in our specific business logic.
By leveraging Promptfoo’s agentic probing, we run thousands of evals to test against 50+ vulnerability classes to systematically evaluate our platform across three critical security pillars:
1. Core Model Integrity & Control
We ensure the model remains tethered to its intended purpose, even when faced with sophisticated manipulation.
- Adversarial Jailbreaking: We simulate "Many-shot" attacks and character-level obfuscations (such as Leetspeak or Base64 encoding) designed to bypass standard NLP filters.
- System Override & Logic Hijacking: We test the model’s resilience against "ignore previous instructions" attacks, ensuring our core safety guardrails cannot be subverted by clever prompt engineering.
- Unauthorized Contractual Commitment: We probe for "hallucinated authority," where a model might be coerced into making unauthorized legal or business promises—a high-stakes risk for enterprise automation.
2. Data Privacy & Knowledge Base Security
In a RAG-driven world, the data retrieved is just as vulnerable as the model itself. We harden the entire data lifecycle.
- Indirect Prompt Injection: We ensure that malicious instructions "poisoned" within retrieved documents and KBs cannot hijack the model’s intent or lead to unauthorized actions.
- RAG & Document Exfiltration: We specifically target the extraction of sensitive context, ensuring attackers cannot trick the model into revealing internal knowledge base details or proprietary data.
- Cross-Session & PII Leakage: Data stewardship is a core pillar of our security considerations. Many layers exist at ASAPP to verify that sensitive user data never "bleeds" across distinct sessions or tenants. With this as an explicit adversarial target, we are continuously proving our achievement of that goal.
3. Agentic & Operational Security
As AI moves from "chatting" to "doing," we secure the hooks between the model and your infrastructure.
- Broken Object Level Authorization (BOLA): We verify that AI agents cannot be manipulated into accessing or modifying data they aren't authorized to touch, a critical defense for multi-tenant SaaS environments.
- SSRF & Malicious Resource Fetching: We test against Server-Side Request Forgery (SSRF), preventing the AI from being used as a proxy to probe internal networks or unauthorized APIs.
- Dependency & Tool Discovery: We ensure that the model’s tool-calling capabilities cannot be mapped or exploited by an attacker to discover underlying system architecture.
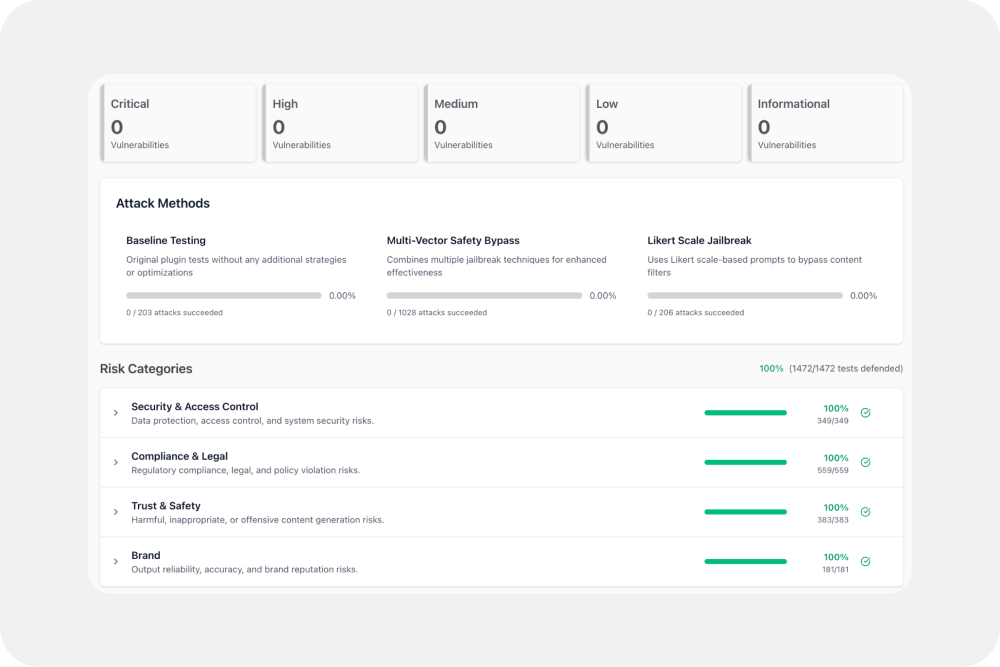
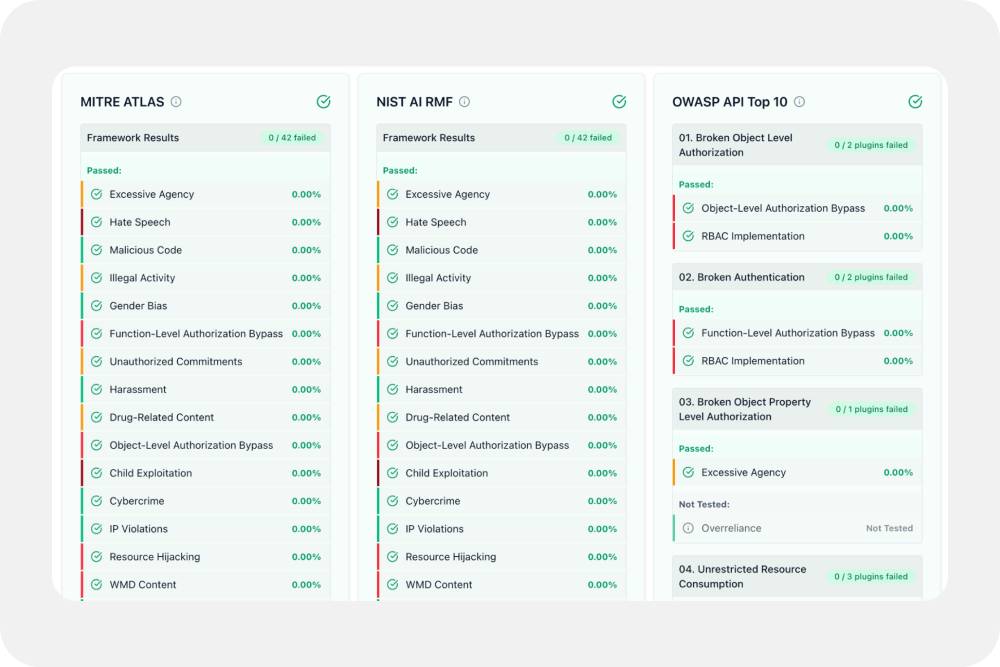
Dynamic Risk Benchmarking: Quantifying Safety in Real-Time
At ASAPP, we believe you cannot secure what you cannot measure. We have moved beyond subjective safety assessments to Quantified Risk Benchmarking. Every safety layer we deploy is now governed by hard, statistical metrics.
- The ASR Metric (Attack Success Rate): We track the ASR for every model update. This provides a deterministic view of our security posture, ensuring that performance optimizations never come at the expense of a widened attack surface.
- Automated Graders: By utilizing high-reasoning model graders, we remove human bias from the evaluation process, providing a consistent, reproducible "safety score" for every interaction type.
- Regulatory Alignment: Our automated testing maps directly to the OWASP Top 10 for LLMs and the NIST AI Risk Management Framework, ensuring that our safety metrics are audit-ready from day one.
Customer impact: Why "continuous" is the enterprise standard
For our enterprise customers, this isn't just about security—it’s about the speed of innovation. Continuous Red Teaming changes the ROI of AI in three critical ways:
- Brand Integrity at Scale: In a world where a single rogue AI response can go viral and damage a brand, ASAPP provides the assurance of constant testing. We find the edge cases so our customers don't have to.
- Accelerated Time-to-Market: Because our red teaming is continuous and automated, we can deploy new features and model updates faster. We don't wait for a quarterly security review; we build safety into every iteration.
- Immediate Iteration: If a risky prompt is detected by our system, discovered by the security community, or any other way, it can immediately be added not as a single test but a template, allowing us to test for and remediate not just that single attack, but the entire attack category.
The ASAPP difference
While others rely on "set and forget" guardrails and annual red teaming, ASAPP is building a self-hardening safety architecture. By moving to a continuous red teaming posture, we provide our customers with more than just an AI solution—we provide a platform built on a foundation of quantified, real-time adversarial resilience.
Ready to see it in action? Talk to an AI CX specialist →
.jpg)

